Windows Server“8”Beta:Hyper-V 和扩展虚拟机,第 1 部分
Microsoft 最吸引我的地方在于对客户的极度重视。在加入 Microsoft 之前,我大部分的职业生涯都投入在为 Microsoft 的竞争对手工作中。Microsoft 面向某个市场发布新产品时,有时候会立即抢占市场,有时则不会。我们故意无视新产品的优势,为能挑出他们的缺陷感到高兴,为我们在某些方面超越他们感到欢欣鼓舞。但在 Microsoft 推出 V3 之前,我们仍旧制定了出售股票期权的计划。我低估了 Microsoft 对客户意见的关注程度,以及他们不遗余力地满足客户一切需求的勇气。Hyper-V 一直是一项出色的功能,十分受客户欢迎,但我们仍然有些后续工作要做。我们一直坚持聆听客户的声音,不断做出改进。Windows Server“8”采用的是 Hyper-V V3,我相信您一定会喜欢它。
Hyper-V V3 有一个庞大而全面的功能列表,我们将发布一系列博文专门进行探讨。今天我们先从一篇分为两部分的博文开始,重点探讨 Hyper-V 功能的一个方面,即它对扩展虚拟机的支持。单纯从数字来看的确引人注目(32 个逻辑处理器、1TB RAM、64TB 虚拟磁盘),但正如 Jeff Woolsey 将在本篇博文中展示的那样,提高性能并不只是增大这些数字那么简单。Jeff 介绍了 Hyper-V V3 中提供的虚拟 NUMA(非一致性内存访问)支持。过去,NUMA 作为一种新潮的技术仅用在超级高端的服务器上,但现在几乎所有服务器都采用这种技术,因此提供相应的支持也变得十分重要。今天看来似乎很新潮和高端的事物,到了明天就变成了常见和必备的事物。许多工作负荷(例如 SQL Server)都利用 NUMA 的优势来提高可扩展性和性能。
在看到我们的 V3 的扩展数字和 NUMA 支持时,您可能认为这些远超您目前的所需。最重要的是,有了 V3,您就再也不用担心有哪些工作负荷是可以虚拟化的,哪些不能。Hyper-V V3 使您能够轻松虚拟化所有工作负荷,还能够满足将来可能出现的新的资源要求。建议您下载 Beta 版本,亲自验证它的强大。
本博文由 Windows Server 团队的首席项目经理 Jeff Woolsey 撰写。
虚拟化一族,你们好!
首先,Windows Server 团队全员对你们表示衷心的 感谢 。
自几周前发布 Windows Server“8”Beta 以来,来自世界各地的反馈如潮水般涌来,Windows Server 中的所有技术以压倒性优势赢得了全球用户的一致好评。对此,我们激动万分,同时以谦卑的态度接受这些赞誉。
再次感谢。
我们来谈一谈扩展
在 Windows Server“8”的开发过程中,一个核心目标是创建最优秀的云平台。无论是部署在小型、中型、企业级还是超大托管云基础架构中,我们都希望能帮助您对业务进行云优化。创建最好的云平台的一个方面是能够在 Windows Server Hyper-V 上托管大部分工作负荷。今天,借助 Windows Server 2008 R2 Hyper-V,我们可以轻松支持虚拟化您的大部分工作负荷,但同时,我们也意识到您希望虚拟化更大型的扩展工作负荷,这些负荷可能需要数十个内核和数百 GB 的内存,并且很可能连接 SAN,且具有极高的网络 I/O 要求。
Windows Server“8”Hyper-V 正是针对这类工作负荷而设计。
扩展并不只是增加虚拟处理器
我经常听到的一个有关 Hyper-V 的问题是:“Hyper-V 何时能支持 4 个以上的虚拟处理器?我需要此功能来处理我的扩展工作负荷。”尽管可以理解客户为何会有此疑问,但这仍然只是个表面问题,没有全面地看待问题。让我们退一步离开虚拟化,讨论一下使用物理服务器的情景。
假设您部署一个具有 8 个套接字的全新物理服务器,每个套接字对应 10 个采用了对称多线程 (SMT) 技术的内核,因而共有 160 个逻辑处理器 (8 x 10 x 2),但该服务器所配备的内存仅为 1 GB。在 1 GB 内存的限制下,逻辑处理器的个数变得无关紧要,因为内存不足,根本无法充分利用计算资源。因此,您增加了 512 GB 内存来帮助解决内存瓶颈。
但是,仍然只配备了两个 1 Gb/E 网络接口卡 (NIC),因此您仍然会受到网络 I/O 限制。接着,您又增加了 4 个 10 Gb/E NIC 来帮助解决网络 I/O 瓶颈。然而,您的系统只配备了少数几个硬盘,因此又出现了另一个瓶颈…
问题显而易见。
提高性能和实现扩展的关键在于 平衡 。您需要以全面的眼光来看待整个系统。您需要兼顾计算、内存、网络和存储 I/O,并一举解决所有问题。增加虚拟处理器并不一定能提高整体性能或实现扩展。
在研究创建大型虚拟机时,我们着眼于整体要求,力图提供性能卓越的扩展虚拟机。在本文中,我们将重点关注 CPU 与内存之间的重要关系。这就意味着我们需要探讨一下非一致性内存访问 (NUMA)。在讨论 Hyper-V 和扩展虚拟机之前,我们先来看一下物理服务器上的 NUMA。
非一致性内存访问 (NUMA)
什么是 NUMA?NUMA 在设计上已经突破了传统对称多处理 (SMP) 体系结构的可扩展性限制。通过传统 SMP,所有内存访问都会传递到同一个共享内存总线,每个处理器对内存和 I/O 都具有相同的访问权限。(顺便提一下,在大约 10 年前,NUMA 系统并不常见,但随着多核、多处理器系统的兴起,NUMA 现在得到了广泛应用。)在 CPU 数量相对较少时,传统 SMP 可以满足需求,但当多个计算资源对共享内存总线竞争访问时,很快就会出现问题。当线程多达几十个甚至数百个时,情况会变得更糟…
NUMA 设计为通过将计算资源和内存分组到不同的节点来解决这些瓶颈。然后通过缓存一致的总线连接每个节点。与当前运行进程的 CPU 位于同一 NUMA 节点的内存称为本地内存,而任何不属于当前正在运行的进程所在的节点的内存均被视为远程内存。最后,之所以称为非一致性,是因为处理器访问其本地内存时会比访问远程内存更快。下面是一个包含四个 NUMA 节点的系统的简单示例。
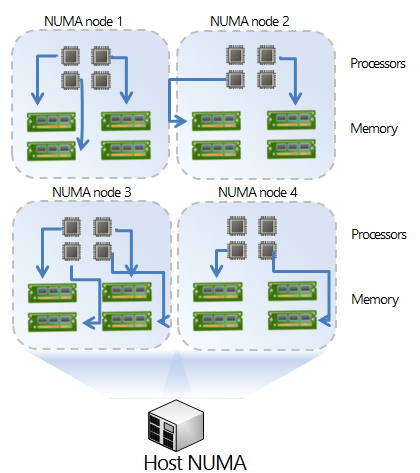
图 1:最佳 NUMA 配置
图 1 展示了一个最佳 NUMA 配置。称其为最佳的原因包括:
1. 系统实现了平衡。每个 NUMA 节点都配备有相同大小的内存。
2. CPU 和内存分配在同一个 NUMA 节点中进行。
下面我们用一个非最佳的 NUMA 配置来进行对比。
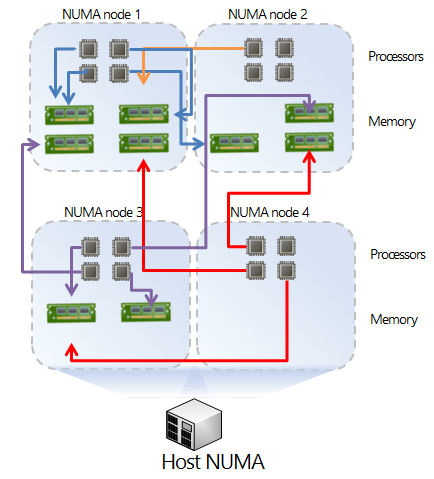
图 2:非最佳 NUMA 配置
图 2 展示了一个非最佳的 NUMA 配置,而它不是最佳的原因在于:
1. 系统不平衡。每个 NUMA 节点的 DIMM 数目各不相同。
2. NUMA 节点 2 的 DIMM 数量为奇数,这意味着即使系统有能力使用内存交错,也很可能无法实现,因为 DIMM 不是成对安装的。(这还取决于主板交错要求:成对、三个一组等。)
3. NUMA 节点 2 和 3 的本地内存不足,也就是说,对于节点而言,一部分内存访问是本地的,而另一部分则是远程的。这会导致不一致、非线性的性能。
4. NUMA 节点 4 没有本地内存,因而所有内存访问均是远程的。这是最糟糕的情况。
SQL Server 如何使用 NUMA
正如您在上面的示例中所看到的一样,计算和内存资源的不断增加是一把双刃剑。一方面,工作负荷有了更多可用资源,但另一方面,操作系统和应用程序必须管理额外的复杂性来实现一致的扩展和更高的性能。根据这些独特要求,扩展工作负荷逐渐发展为“可识别 NUMA”。Microsoft SQL Server 就是一个很好的例子。从 SQL Server 2005 开始,SQL Server 就能够识别 NUMA,并充分利用 NUMA 的优势。本篇 MSDN 文章提供了深入介绍:
SQL Server 对计划程序进行分组,以根据 Windows 所显示的硬件 NUMA 边界将这些计划程序映射到 CPU 的分组。例如,16 路逻辑单元有 4 个 NUMA 节点,每个节点有 4 个 CPU。这使得在节点上处理任务时,该组计划程序具有更多的本地内存。使用 SQL Server,您可以进一步将与硬件 NUMA 节点关联的 CPU 细分为多个 CPU 节点。这称为软件 NUMA。通常,您将细分 CPU 以跨 CPU 节点对工作进行分区。有关软件 NUMA 的详细信息,请参阅了解非一致性内存访问。
当特定硬件 NUMA 节点上运行的线程分配内存时,SQL Server 的内存管理器将尝试从与 NUMA 节点关联的内存分配内存以进行本地引用。同样,缓冲池页将跨硬件 NUMA 节点进行分布。线程从分配到本地内存的缓冲区页访问内存比从外部内存进行访问效率更高。有关详细信息,请参阅使用 NUMA 扩展和收缩缓存池。
每个 NUMA 节点(硬件 NUMA 或软件 NUMA)都有一个用于处理网络 I/O 的相关 I/O 完成端口。这有助于跨多个端口分布网络 I/O 处理。当某个客户端连接到 SQL Server 时,将绑定到其中一个节点。此客户端的所有批处理请求都将在该节点上处理。每次在 NUMA 环境中启动 SQL Server 实例时,SQL 错误日志都包含说明 NUMA 配置的信息性消息。
遍历 NUMA 节点和远程内存
您也许想知道:“遍历 NUMA 节点会对性能产生多大影响?”对此并没有确切的答案,因为这是由许多不同因素决定的。其中包括:
1. 系统是否平衡?如果从一开始系统就配置不佳并且不平衡,那么任何软件都没有魔法来力挽狂澜。(我把这列为第一条原因…)
2. 工作负荷能否识别 NUMA?例如,SQL Server 可以识别 NUMA,也就是说,它识别底层 NUMA 拓扑,并尝试尽可能在最优物理位置执行 CPU 和内存分配。
3. 物理服务器是在处理器中集成了内存控制器的新型服务器,还是具有前端总线 (FSB) 的旧式物理服务器?如果是后者,而您又需要遍历前端总线中的 NUMA 跃点,那么就会严重影响性能…
需要记住的重要一点是,为了构建最佳的扩展系统,您希望确保尽可能在最优物理位置进行 CPU 和内存分配。实现这一目标的最佳做法就是构建一个平衡的系统。这是对物理服务器上的 NUMA 的简要介绍。现在我们向组合中加入 Hyper-V。首先,我们来简单探讨一下早期版本 Hyper-V。
NUMA、Windows Server 2008 R2 SP1 Hyper-V 及早期版本
在 Windows Server“8”之前的版本中,Hyper-V 的 NUMA 感知能力是 从主机角度 来讲的。也就是说,虚拟机监控程序在最优物理位置分配内存和 CPU 资源。默认情况下,Hyper-V 资源位置基于以下模式:通常,客户的工作负荷更多地受内存性能约束,而不是原始计算能力。将一个虚拟机完全部署在一个 NUMA 节点上可以使该虚拟机的内存全部为本地内存(假设可以按这种方式分配),从而达到最佳的整体内存性能。
下面是一个简单的示例。在本例中,假设我们有一个具备 4 个活动虚拟处理器的虚拟机,其平均 CPU 利用率在 75% 以上。在 Windows Server 2008 R2 或 Windows Server 2008 R2 SP1 中,如果我们创建了一个具有 4 个虚拟处理器的虚拟机,Hyper-V 将执行以下操作:
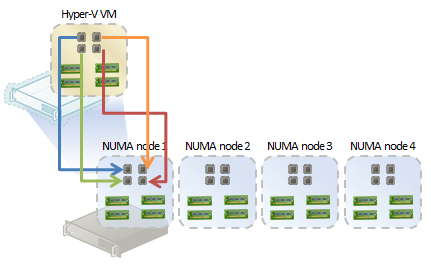
图 1:Windows Server 2008/2008 R2 中具有 4 个虚拟处理器的虚拟机
如图 1 所示,Hyper-V 创建一个虚拟机,并在一个 NUMA 节点中以最佳方式分配资源。所有 CPU 和内存分配均在本地完成。下面的示例与此形成鲜明对比:
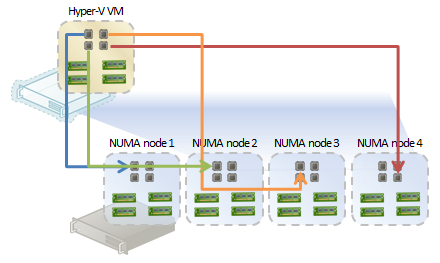
图 2:非最佳计划示例(与 Hyper-V 所执行的操作不同...)
图 2 所示的配置需要执行大量遍历 NUMA 节点的操作。
从 虚拟机 的角度来讲,Hyper-V 不会在虚拟机内部提供 NUMA 拓扑。虚拟机中的拓扑看起来是一个全部内存均为本地内存的 NUMA 节点,而不考虑物理拓扑是何情况。在实际应用中,缺少 NUMA 拓扑对于 Windows Server 2008 R2 SP1 Hyper-V 及早期版本而言并不是问题,因为在单个虚拟机中可以创建的最大虚拟处理器数量为 4 个,最大可分配内存为 64 GB。这两方面都适合现有的物理 NUMA 节点,因此为虚拟机提供 NUMA 迄今为止都不是问题。
可扩展性信条
在我们深入探讨此版本的 Hyper-V 带来了哪些变化之前,先来看一下有关可扩展性的重要信条:
>> 增加内核数量应该可以提高性能。<<
我相信这听起来是显而易见的事情,您也一定是基于这样的期望才购买了多核系统;然而,在某种情况下,增加内核数量可能会限制甚至降低性能,因为同步内存所需的代价超出了额外内核所带来的好处。下面我通过两个例子来阐明我的观点(其中数据仅用作示例)。
假设您在 32 路系统 ($$$$) 上部署了工作负荷,结果发现:
• 在示例 A 中:工作负荷性能止步于 8 个处理器的水平?更糟的是,
• 在示例 B 中:工作负荷性能在 8 个处理器时达到峰值,在更多处理器时反而下降?
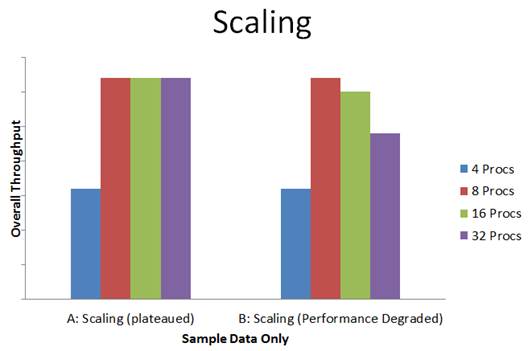
您是否对此大型扩展系统的投资回报率感到失望?
我也有同感。
您 真正期望 的是尽可能实现接近线性的扩展,如下所示:
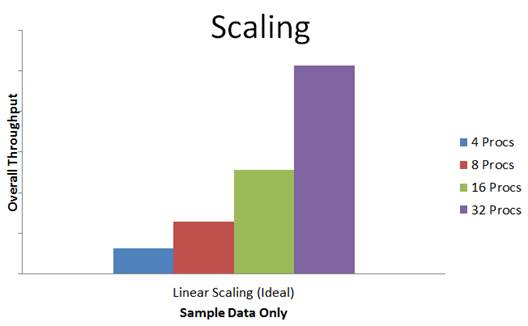
我们期望借助此版本的 Hyper-V 扩展虚拟机,创建具有 12 个、16 个、24 个甚至 32 个虚拟处理器的虚拟机,我们知道必须改变现状。由于每个虚拟机的虚拟处理器数量超出了 NUMA 节点中的物理处理器的数量,单独的主机端 NUMA 无法使我们将硬件利用率提到最高。最重要的是,我们希望确保来宾工作负荷能够获得最佳信息,从而以最高效的方式工作,并与 Hyper-V 协作提供最佳的可扩展性。为此,我们需要在虚拟机中启用 NUMA。
Windows 8 Hyper-V:虚拟机 NUMA
通过此版本的 Hyper-V,我们向虚拟机中引入了 NUMA。虚拟处理器和来宾内存分组到各个虚拟 NUMA 节点,虚拟机根据计算和内存资源的基础物理拓扑为来宾操作系统提供拓扑。Hyper-V 使用 ACPI 静态资源关联表格 (SRAT) 作为一种机制,向所有处理器和的内存提供拓扑信息,描述系统中处理器和内存的物理位置。(附注:使用 ACPI SRAT 提供 NUMA 拓扑是一种行业标准,这意味着 Linux 和其他可识别 NUMA 的操作系统也可以利用 Hyper-V 虚拟 NUMA。)
借助虚拟 NUMA,来宾工作负荷可以使用其 NUMA 信息并根据该数据进行自我优化。这意味着 Hyper-V 与来宾操作系统协同工作,在虚拟资源和物理资源之间创建最好、最佳的映射,进而使应用程序可以确保最高效的执行、最佳的性能和最线性的扩展。此外,对于必须在不同的物理NUMA拓扑系统之间迁移的虚拟NUMA拓扑,Hyper-V 还提供精细的配置控制。要提供跨各种不同 NUMA 拓扑的可移植性,用户必须确保虚拟拓扑可以映射到虚拟机将迁移到的所有目标机器的物理拓扑。
宏观来看,具备两个中高负荷(75% 以上)的虚拟机时的情况如下:
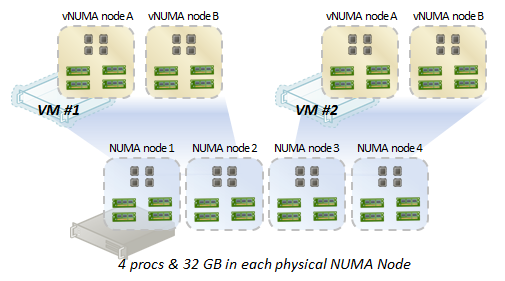
正如您所看到的:
• 虚拟机 1 NUMA 节点 A 和 B 对应物理 NUMA 节点 1 和 2
• 虚拟机 2 NUMA 节点 A 和 B 对应物理 NUMA 节点 3 和 4
我们来深入分析一下。
虚拟 NUMA 示例
在本例中, 物理 系统配置为:1 个套接字,带有 8 个内核和16 GB 内存。在我创建新的虚拟机时,Hyper-V 会识别底层拓扑,并创建一个按以下方式配置 NUMA 的虚拟机:
• 每个 NUMA 节点的最大处理器数量 = 8
• 每个 NUMA 节点的最大内存 = 13730(此数值是使用总内存减去为根保留的内存计算得出)
• 一个套接字上允许的最大 NUMA 节点数 = 1
配置情况具体如下:
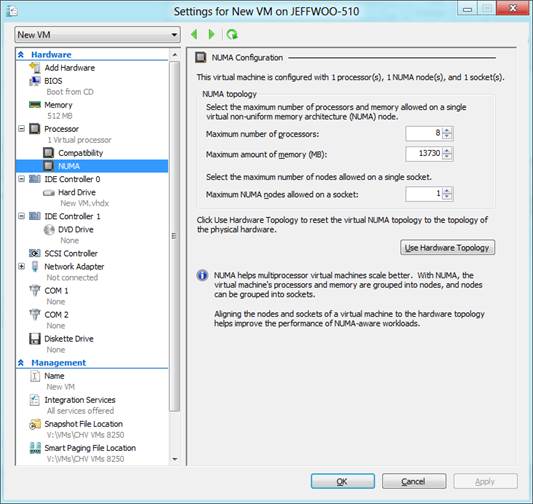
这是对此物理系统而言最佳的虚拟 NUMA 拓扑。此时您也许会疑惑,这不是表示我们把系统复杂化了吗?我需要开始计算所有服务器中的内核、DIMM 套接字数量吗?
答案是否定的。这里有一点非常重要:
>> 默认情况下,Hyper-V 会自动执行正确的操作。<<
创建虚拟机时,Hyper-V 识别底层物理拓扑,并根据许多不同因素自动配置虚拟 NUMA 拓扑,这些因素包括:
• 每个物理套接字的逻辑处理器数量(一个逻辑处理器相当于一个内核或线程)
• 每个节点的内存大小
此外,我们还提供了适用于不太常见的情况的高级配置选项。这些高级设置可以帮助您在具有不同 NUMA 拓扑的硬件之间移动虚拟机。尽管这种情况并不常见,但我们希望通过提供这些高级功能,能够为客户提供他们所需的最大灵活性。在下篇博文中,我们将介绍根据客户反馈将 Windows Server 8 Developer Preview 改进为 Windows Server“8”Beta 所进行的更改。