SQL Server: Transactional Replication Resynchronization
Introduction
Initializing transactional replication for the first time or reinitializing when it goes out of sync can be frustrating but knowledge and planning can take most of the pain out of it. This guide is designed for SQL Server database administrators to synchronize transactional replication subscriptions quickly and efficiently. It requires a working knowledge of replication and administration concepts including:
- Database Backup and Restore
- Full, Differential, and Transaction logs
- Replication Concepts
- Publisher, Distributor, and Subscribers
- Publications and Subscriptions
- Publication and subscription options
- Replication Agents and jobs
If you aren't sure about these concepts I'd recommend creating a couple of regular transactional replication push publications on a non-production machine with read-only subscriptions and play around with the different settings and agent jobs.
Most scenarios covered involve push replication with read-only subscribers because it tends to be the most common setup. They should work similarly for peer-to-peer and updating subscribers but would need to be updated accordingly.
Background
The crux of the synchronization problem boils down to two main tasks:
- Getting the initial data to the subscriber
- Creating the subscription metadata in the publishing, distribution, and subscription databases
The glue that binds the process together is the log sequence number (lsn) from the publisher database and this is how SQL server keeps track of where it's at. I tend to make a lot of references to time and what I usually mean is at a specific lsn at the publisher database.
In addition to these requirements the process should meet secondary objectives:
- Minimize the complexity involved with synchronization
- Minimize disruptive activity on the publisher
- Minimize impact to the business environment
- Minimize the time needed to synchronize
Making a mistake during initialization tends to punish harshly, typically with a lot of late nights and weekends figuring out what went wrong, how to fix it, and explaining it to downstream customers.
Getting the initial dataset to the subscriber
This process starts by getting a consistent snapshot of all of the articles from the same point in time at the publisher and applying it to the new subscriber. Usually this is done by the snapshot agent or from a database backup. It could also be done by directly copying tables but this tends to be time consuming and also introduces the problem of data consistency since you can synchronize the entire process to a specific lsn. There's a possibility of using a backup from a different database (perhaps another subscriber), but we can't use the lsn from that file since lsns are specific to an instance of a database and we require the lsn from the publisher.
Just as important is ensuring that transactions after the initial lsn and before the initial synchronization are not lost. The worst part about this is that we usually don't discover this until we try to create the subscription and get a message that looks something like this:
Msg 21397
The transactions required for synchronizing the nosync subscription created from the specified backup are unavailable at the Distributor. Retry the operation again with a more up-to-date log, differential, or full database backup.
The usual suspects for missing data in this time frame are:
- Publication doesn't exist: The publication needs to exist so that there is a start point for synchronization, and it needs to have existed before the time the initial data snapshot is taken.
- Distribution Cleanup Agent: This is the job that runs on the distributor and dutifully cleans up transactions that have already been applied at all subscribers. The problem occurs because the minimum transaction retention period is set to 0 by default. Since the subscription usually does not yet exist while copying the data, it removes the transactions as soon as all of the other subscribers have applied them. You can disable this job during the process, or you can set a minimum retention time.
|
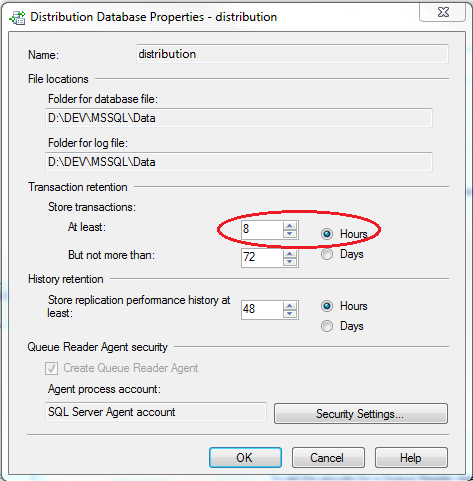
The number of commands between the lsn of the backup and the current lsn at first synchronization is critical because all of that information needs to be stored at the distributor until it's applied. The more commands waiting the worse the performance will be when SQL reads, applies, and then cleans up this chunk of data. This is why it's important to minimize the synchronization time as much as possible. This is also a reason against having a large minimum retention time.
Since we can synchronize from any backup file including a transaction log backup, the easiest trick to minimize the time lag is to restore differential and logs to bring the database as close to the current time as possible. The other bonus is that these operations are largely parallelizable since we can copy the diff and log files at the same time the full is restoring.
A second important trick to minimizing time lag is to create scripts while the data is copying / restoring and have them ready to execute when the database is restored.
Creating the publication and subscriptions
Implementing a subscription with any kind of nontrivial synchronization plan requires a lot of verbose scripting and even simple implementations should be scripted for disaster recovery and maintenance purposes. One easy way to do this is by creating something close to what you want in the GUI and using 'Generate Scripts...' on the publication to make scripts which are then modify to a scenario. Keep the entire script for disaster recovery but for the purposes of syncing a new subscriber we are generally only interested in the last two lines:
exec sp_addsubscription @publication = N'MyPub', @subscriber = N'Subserver'[...] exec sp_addpushsubscription_agent @publication = N' MyPub', @subscriber = [...]
Another way is to create templates that support a specific scenario, then use the 'Replace Parameters' function to fill in the Publisher, Subscribers, etc. In addition to saving time these templates reduce the odds of forgetting a critical step during the process which usually results in starting over from the beginning.
The time between determining the initial lsn and creating the subscription is critical because modifications during this period can cause SQL to reject an lsn as unsuitable. Furthermore, starting or stopping replication agents during the process can cause data loss depending on the specific scenario. Being unsure about whether the sync process lost data is often worse than just choosing different sync method because validating that two large distributed data sets are the same can be costly.
SQL 2005 allows no-sync types of 'replication support only' and 'initialize with backup' which limits our options for lsns we can start from. 'Replication Support Only' requires that publisher and subscriber have identical data (i.e. quiesced). 'Initialize with Backup' allows us to start from a different lsn, but not any arbitrary one. SQL 2008 allows option 'initialize from lsn' which does allow any arbitrary valid lsn to be used.
A tempting workaround for the SQL 2005 issue is to create a subscription with a different lsn, and then immediately update it before first synchronization with something like:
EXEC sp_setsubscriptionxactseqno 'Publisher', 'PubDB', 'Publication', <My_arbitrary_lsn>
The difficulty with this approach is that the distribution agent is what sets up the subscription, after which it immediately begins synchronizing. If a method depends on starting exactly from this lsn then there is a risk of introducing data inconsistencies for records applied between the original lsn and the updated one.
It might be possible to try manipulating the lsn by creating the initial subscription with frequency_type = 2 (on demand) so that it doesn't automatically start and then change the subscription_seqno number in the MSSubscriptions table on the distributor. Unfortunately, every experiment I've tried with this has resulted in lost transactions so I wouldn't recommend it, but there are some other ways to work around the problem.
Summary
Synchronizing transactional replication subscriptions involves getting all of the replicated tables to the subscriber with the least amount of effort and disruption. Once everything is in place it becomes a matter of creating the subscription and letting SQL know which lsn it should start processing from.
In the coming weeks I will post info about common replication scenarios and some methods for doing them.