Text Analytics in Python – made easier with Microsoft’s Cognitive Services APIs

 By Theo van Kraay, Data and AI Solution Architect at Microsoft
By Theo van Kraay, Data and AI Solution Architect at Microsoft
Microsoft’s Azure cloud platform offers an array of discreet and granular services in the AI + Machine Learning domain that allow AI developers and Data Engineers to avoid re-inventing wheels, and consume re-usable APIs.
The following is a straightforward Python-based example illustrating how one might consume some of these API services, in combination with using open source tools, to analyse text within PDF documents.
First, we create a Text Analytics API service in Azure. From your Azure subscription (click here to sign up for free) go to Create a resource -> AI + Cognitive Services -> Text Analytics API:
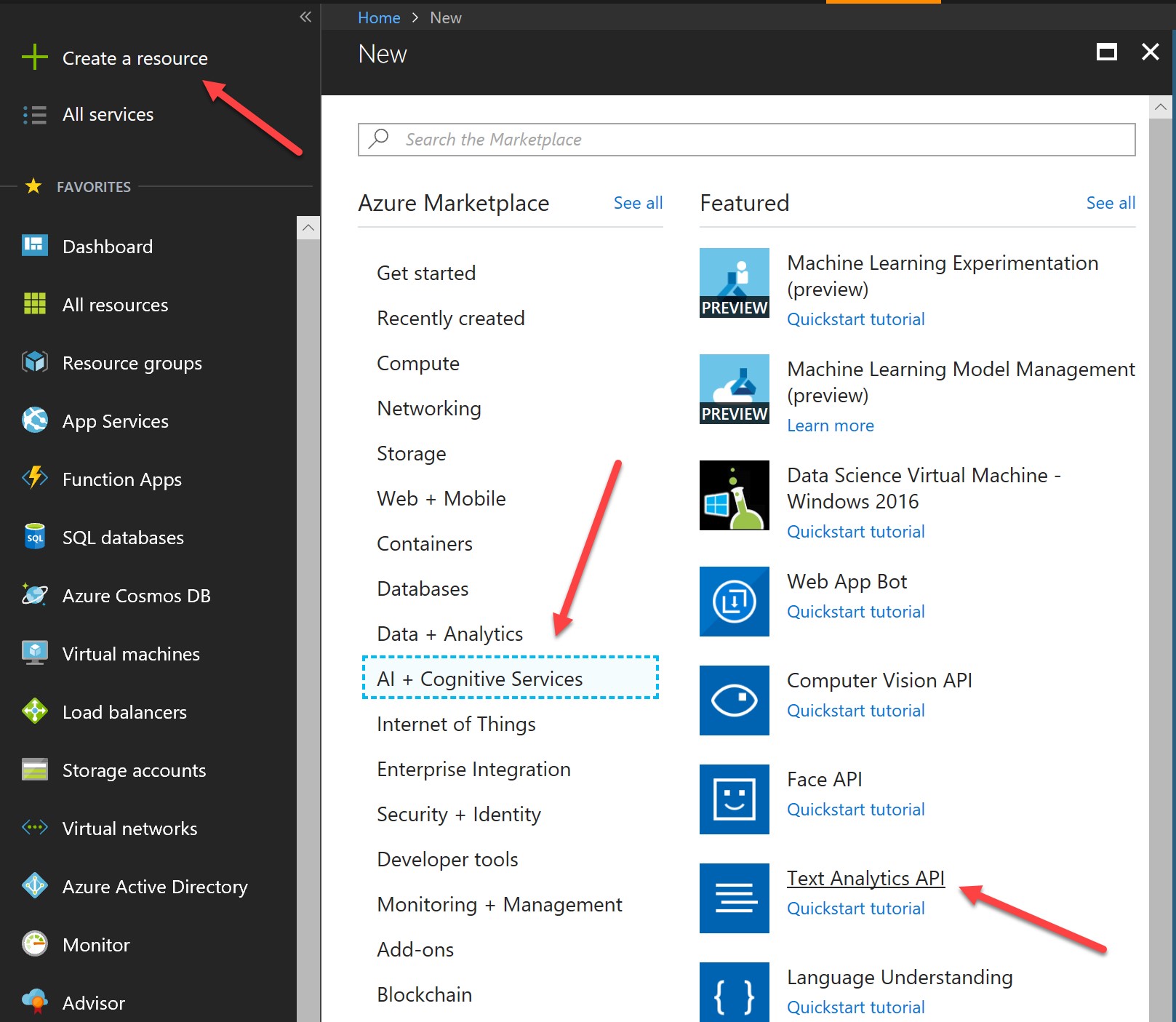
Give your API a unique name, select your Azure subscription and region, select your pricing tier, and select (or create) a resource group for your API:
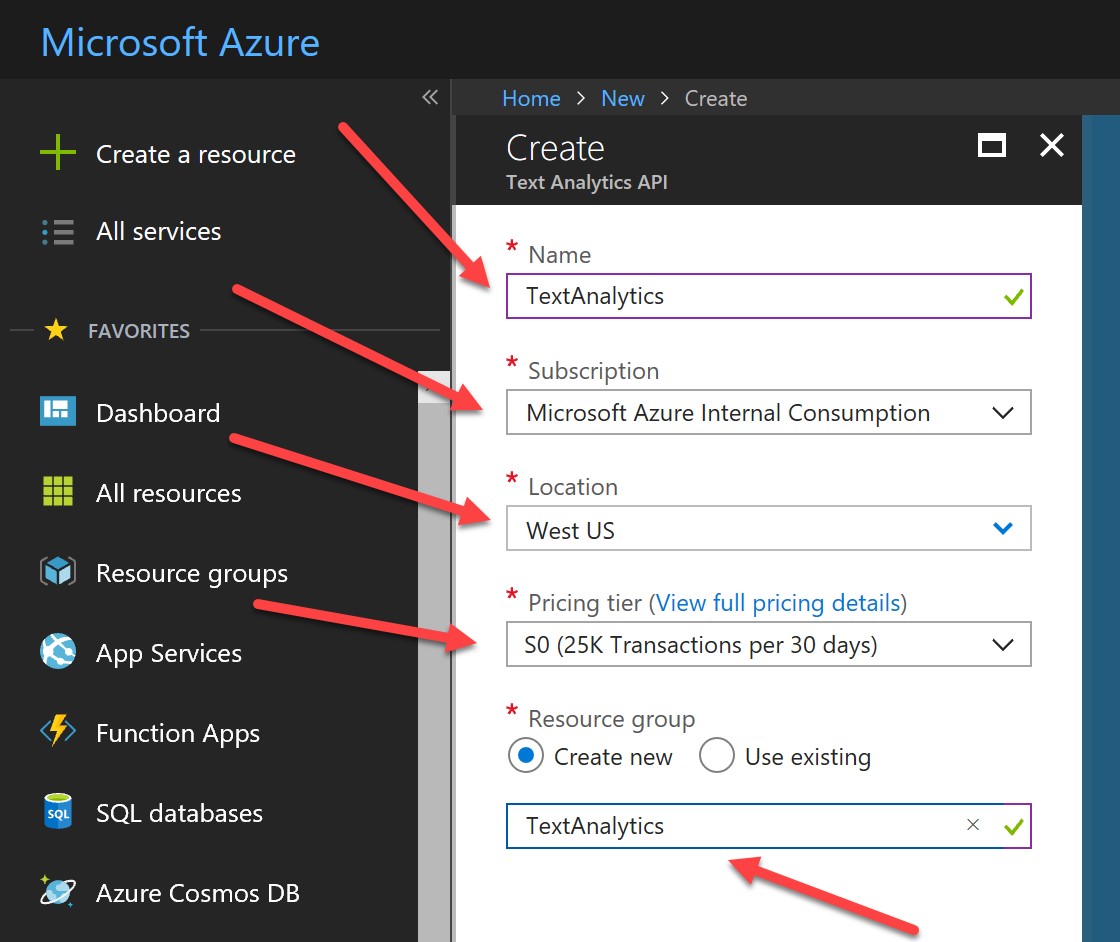
Hit create:
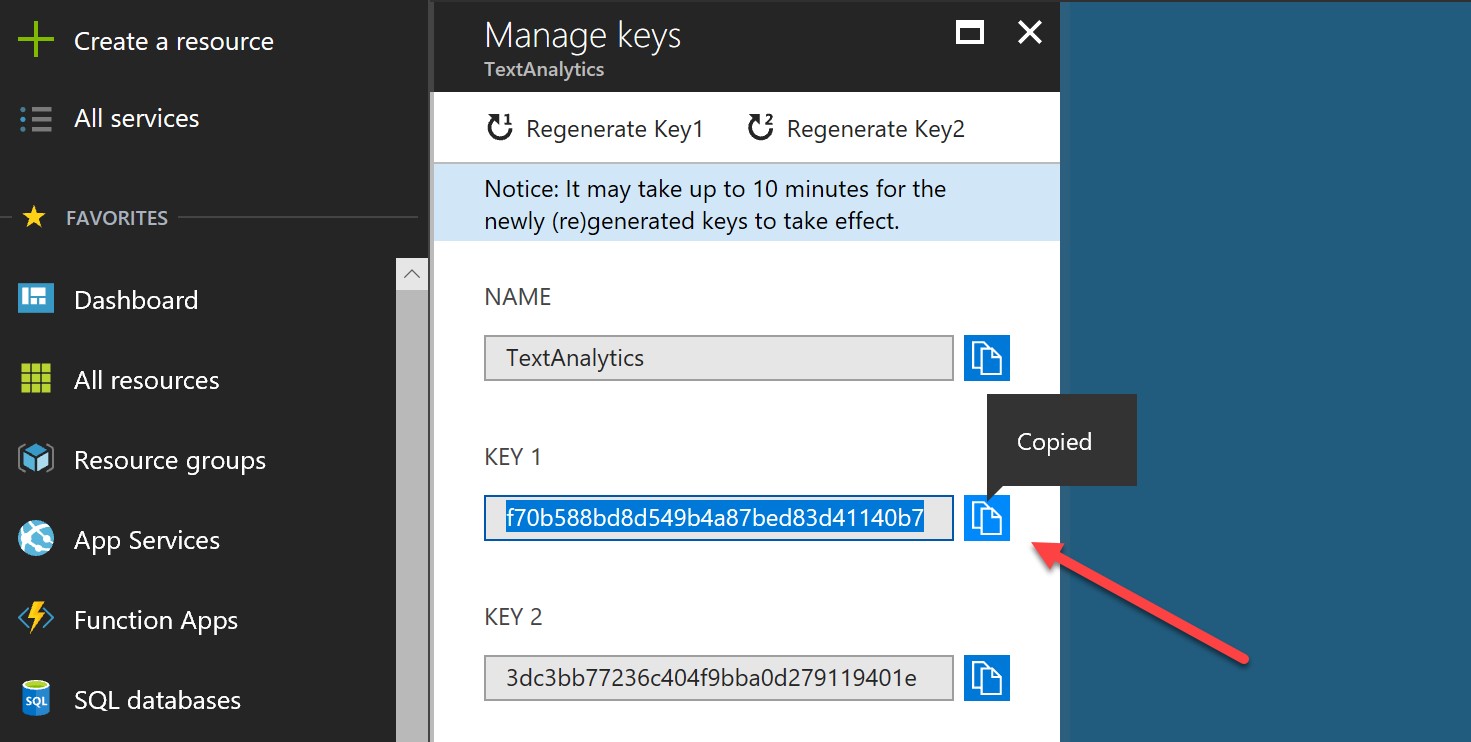
When your resource has been deployed, go into it and you will see the following screen. Take a note of the endpoint, and hit “Keys” to get your API key:
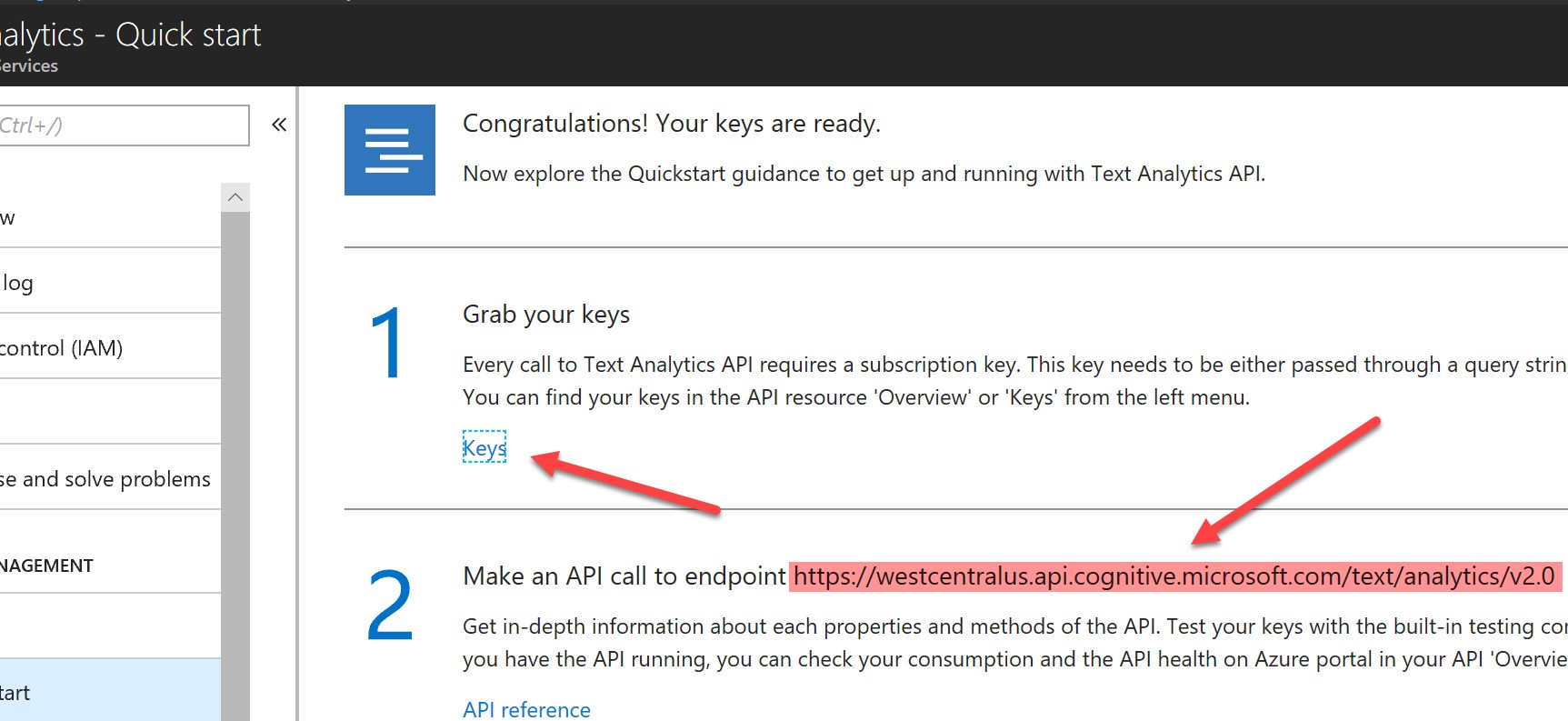
Make a note of the key (either will do):
For Python, I highly recommend Microsoft’s excellent language agnostic IDE, Visual Studio Code (see here for a tutorial on how to configure it for Python – ensure you use a Python 3 distribution). For this example, in your Python code, you will need the following imports (the IDE should highlight to you which modules you need to install):
import urllib.request
import urllib.response
import sys
import os, glob
import tika
from tika import parser
import http.client, urllib
import json
import re
tika.initVM()
Creating a function to parse PDF content and convert to an appropriate collection of text documents (to later be converted to JSON and sent to our API) is straightforward if we make use of the parser in the Tika package:
def parsePDF(path):
documents = { 'documents': []}
count = 1
for file in glob.glob(path):
parsedPDF = parser.from_file(file)
text = parsedPDF["content"]
text = text.strip('\n')
text = text.encode('ascii','ignore').decode('ascii')
documents.setdefault('documents').append({"language":"en","id":str(count),"text":text})
count+= 1
return documents
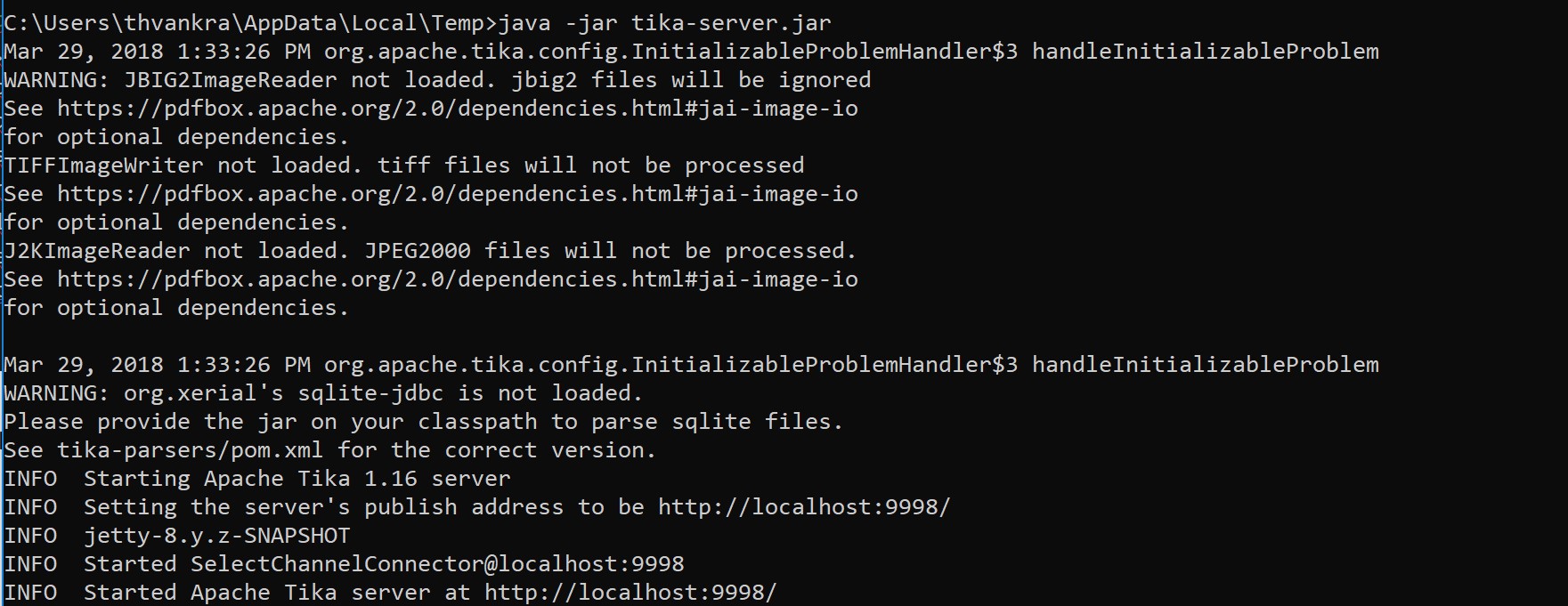
Note that the Python Tika module is in fact a wrapper for the Apache Foundation’s Tika project, which is an open source library written in Java, so you will need to ensure you have Java installed on the machine on which you are running your Python code. While the tika.initVM() call should instantiate a Java Virtual Machine (JVM), you may need to do this manually depending on your environment. If so, simply locate the JAR file (which should have been pulled down as part of installing the Tika module) and start the server. For example, in a Windows environment, run the following from the command line, having navigated to the location of the JAR file:
Java -jar tika-server.jar
Once we are sure we have the pre-requisites for parsing the PDF content, we can setup the access credentials for the Text Analytics API, and create a function that will call it for our documents. Initially, we want to do sentiment analysis for the content of each PDF document, so we specify “Sentiment” as the operation within path:
# Replace the accessKey string value with your valid access key.
accessKey = 'f70b588bd8d549b4a87bed83d41140b7'
url = 'westcentralus.api.cognitive.microsoft.com'
path = '/text/analytics/v2.0/Sentiment'
def TextAnalytics(documents):
headers = {'Ocp-Apim-Subscription-Key': accessKey}
conn = http.client.HTTPSConnection(url)
body = json.dumps (documents)
conn.request ("POST", path, body, headers)
response = conn.getresponse ()
return response.read ()
From there, the code to invoke the functions is simple:
docs = parsePDF("Data/PDFs/*.pdf")
print(docs)
print()
print ('Please wait a moment for the results to appear.\n')
result = TextAnalytics (docs)
print (json.dumps(json.loads(result), indent=4))
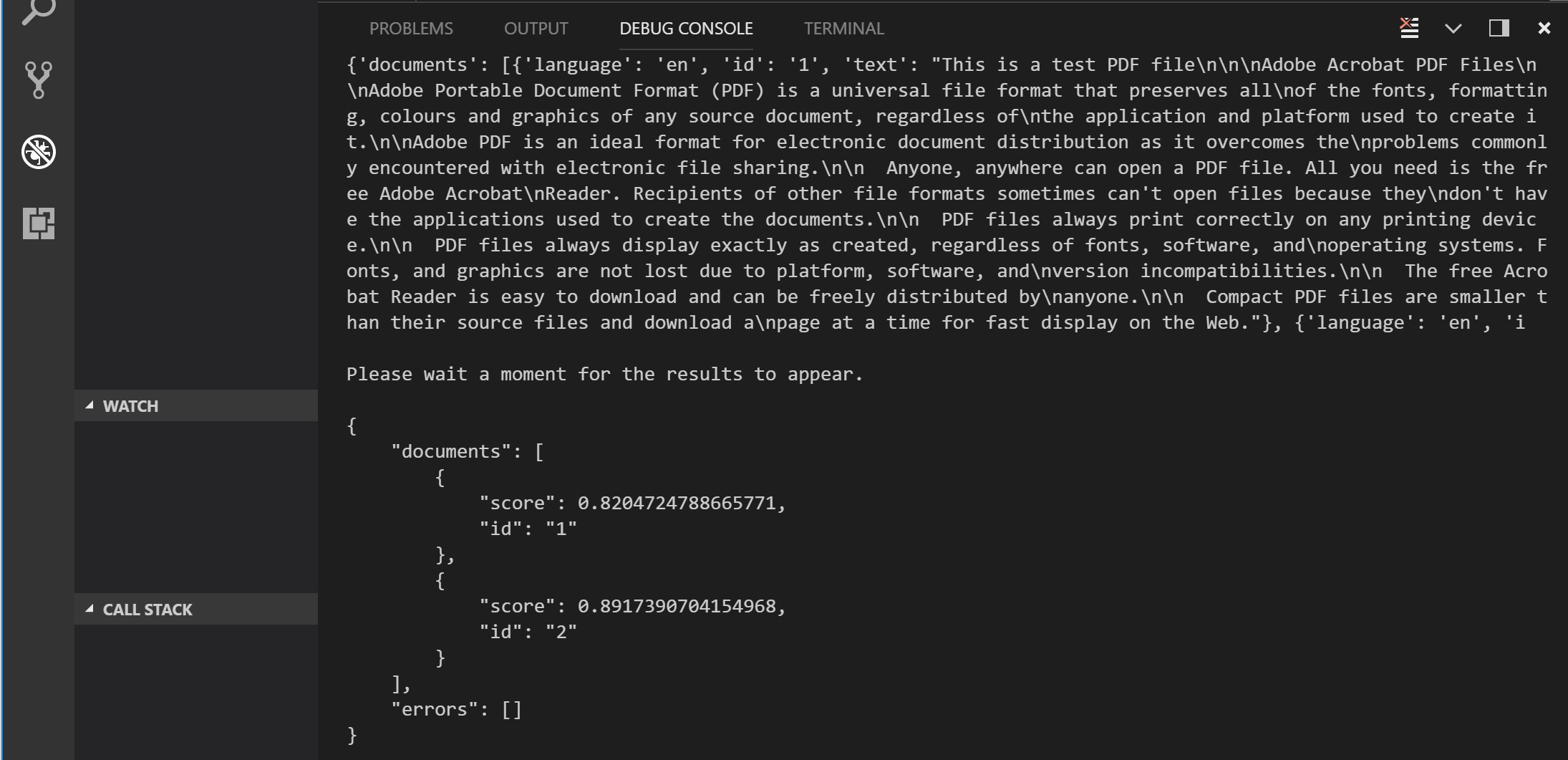
You should see a response something like the below, showing the sentiment score for two PDF documents:
If we want to shift the analytical focus to key phrase learning, we simply change the API operation to “KeyPhrases”:
path = '/text/analytics/v2.0/keyPhrases'
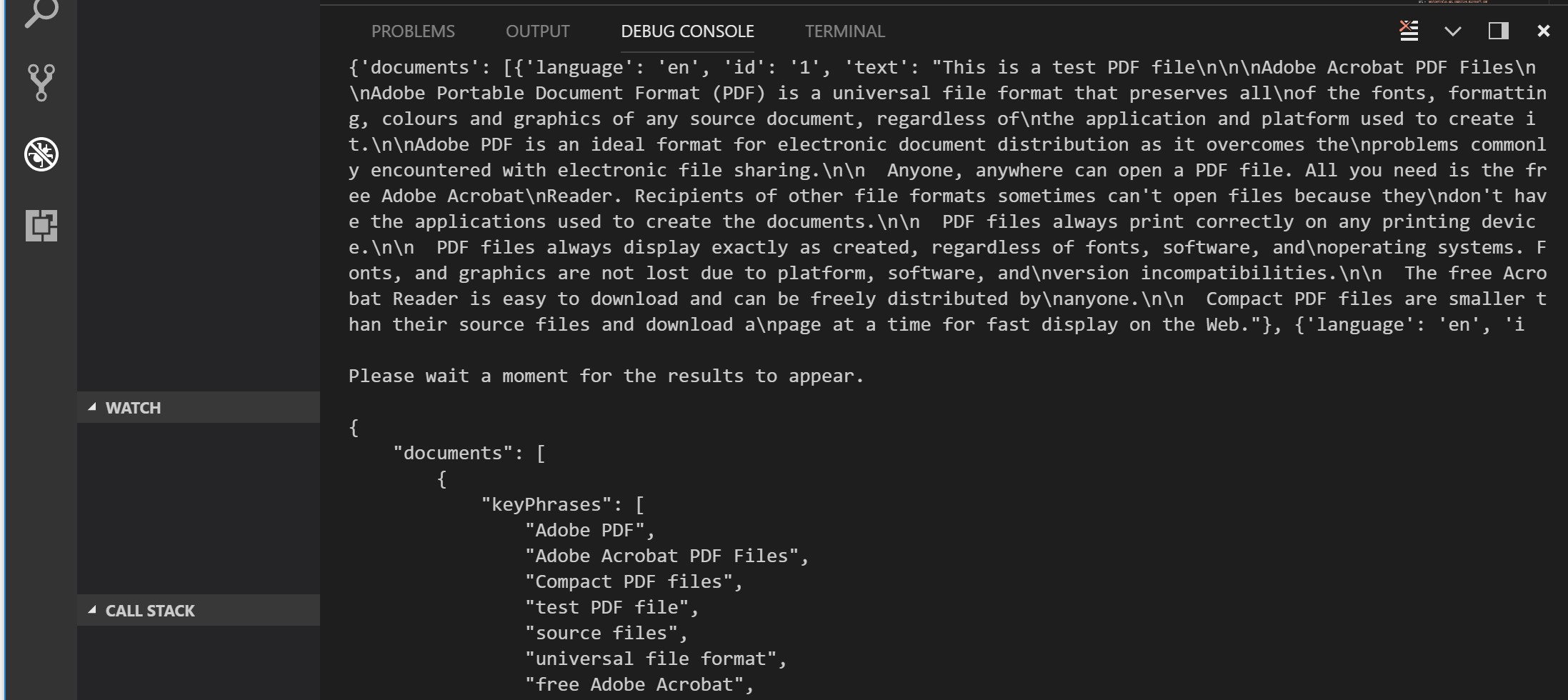
The output would change accordingly:
The Cognitive Services Text Analytics API also supports language detection:
path = '/text/analytics/v2.0/languages'
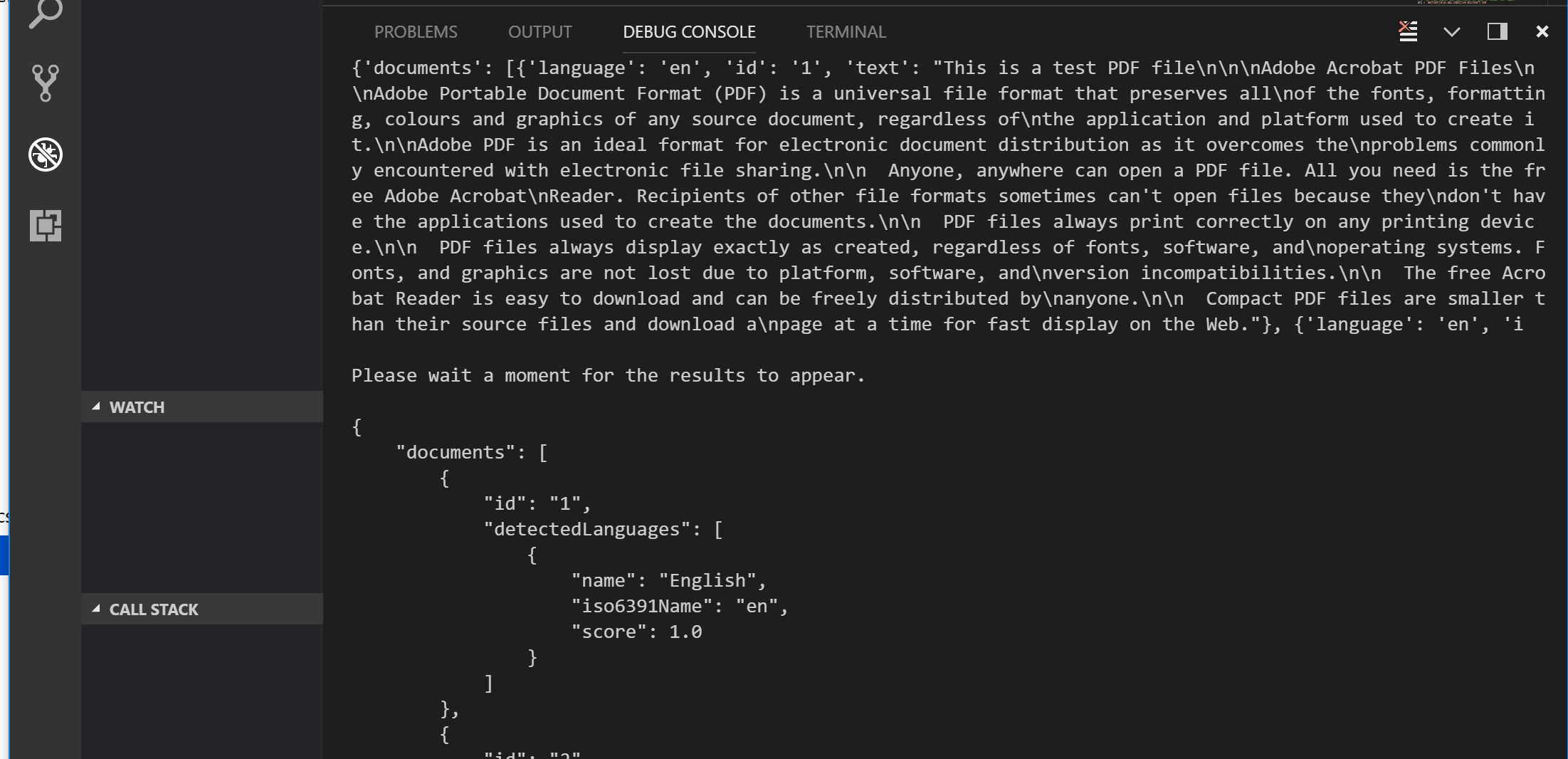
Note that these services do have some upper character limits in terms of documents within a request, and the overall size of a JSON request, so you will need to bear this in mind when consuming the services.
For more samples on using Azure Cognitive Services Text Analytics API with Python and many other languages, see here. To learn more about the full suite of Azure AI & Cognitive Services, see here.