Windows Azure IaaS teljesítmény
A minap kaptam meg kérdésnek, hogy hogyan lehet a Windows Azure IaaS gépek esetén felmerülo teljesítmény szuk keresztmetszetet megtalálni. A válasz: ugyan, úgy ahogy más gépeknél: méréssel és monitorozással (barátunk a perfmon). De ennek kapcsán eszembe jutott, hogy megírom, mi az amire teljesítmény szempontból érdemes odafigyelni az Azure IaaS gépek esetében.
A gép teljesítménye szempontjából a CPU, RAM, diszk és hálózat meghatározó. Ezeken az alapveto „hardver” paramétereken felül a gép teljesítményét negatívan befolyásolhatják szoftver komponensek konfigurációi (single thread alkalmazás, stb, stb.). Mivel a szoftver komponensek konfigurációja nem Azure specifikus ezért azzal ebben a cikkben nem foglalkozom.
A „hardver” paraméterek tekintetében pedig elsosorban azt tartom fontosnak, hogy megértsük miben más egy Azure-ban futó gép, mint az on-premise és mit tehetünk, ha az egy komponensrol kiderül hogy szuk keresztmetszetet jelent. Értsük meg hogy hogy muködik az Azure-ban és akkor egybol tudni fogjuk kezelni a performancia kérdéseket is.
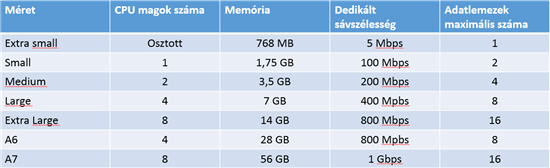
Mielott belekezdenénk, emlékeztetoül egy táblázat a korábbi „Túlterhelés elleni védekezés (DDoS) Windows Azure-ral” cikkbol:
Processzor
Nem gondolom, hogy nagy titkot árulok el ha azt mondom, hogy a CPU-k esetében a teljesítményt ami meghatározza az az, hogy az 2 Ghz-s AMD Opteron CPU magoknak mik a képességei, mivel ha megnézzük egy Azure IaaS-ben futó gép Tulajdonság lapját egybol kiderül milyen CPU fut az Azure gépekben.
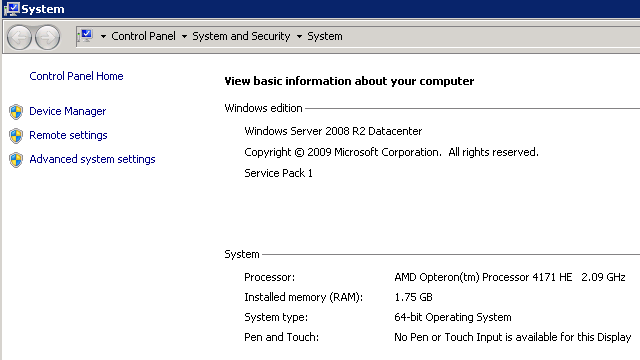
Tehát a CPU-ban nagyjából ezzel az órajellel számoljunk, ha hardver upgrade lesz az Azure környezetben várhatólag ennél nagyobb órajelu gépek fogják változtatni ezt.
Ami a CPU utasítás készletet illeti, nos ha olyan workload-unk van ami egy speciális utasítás készlet meglétét igényli ami nincs benne a fent említett Opteron-ban akkor az nem biztos hogy elso körben ideális jelölt a felhobe, vagy akár virtualizációba konszolidációra. Itt jegyezném, meg hogy nekem csak egy workload jut eszembe, aminek a CPU utasításkészlettel szemben elvárása van, az pedig a Hyper-V, azt meg nyilván nem akarunk/tudunk futtatni az egyébként Hyper-V-n futó Windows Azure-ban.
Amennyiben a CPU esetében látunk szuk keresztmetszetet, akkor a megoldás a további CPU magok hozzáadása lehet. A felho szolgáltatások esetén a magas fokú automatizáció és standardizáltság az alapja a költséghatékonyságnak. Ezért ne is várjuk, hogy valaha egyedileg beállítható CPU mag szám lesz az Azure-ban, mint azt megszoktuk az on-premise világban. Ha kevés az egy mag az „S” gépben akkor váltsunk a két magos „M” gépre, vagy a négy magos „L” vagy A6 gépre vagy 8 magos „XL” vagy A7-es gépre. Ezt csak így lehet hatékonyan kezelni, különben a fabric controllernek bonyolult muveleteket kellene végeznie, hogy melyis gépeket lehet egy fizikai hostra tenni, melyikeket nem. Arról nem is beszélve, hogy a számlázást is teljesen felborítaná és követhetetlenné tenné.
Szóval a CPU teljesítmény problémákat hasonlóan tudjuk kezelni, mint az on premise infrastruktúra esetében, azzal a különbséggel, hogy a gépeknek a CPU száma fix és legfeljebb 8 lehet. Az ennél több CPU magot igénylo load-okat érdemes megvizsgálni, hogy nem lehet-e oldalra skálázással (több virtuális gép) bevonásával elosztani.
Az XS-es géprol meg kell jegyezni, hogy abban az esetében osztott CPU core-van azaz egy core-on több virtuális gép is osztozik, nempedig dedikált core-t kapunk. (tehát a többi méret esetén a core-k dedikált core-k). A CPU szám növeléséhez át kell állítanunk a gép méretét a portálon, ami aztán egy újraindítás után érvényre jut. Ne felejtsük el, hogy a felhoben a lefelé skálázódásnak is szerepe van mivel a nagyobb gép után többet is kell fizetnünk!
Memória
A RAM mérete jelentosen hasonlít a CPU-hoz: fix és a RAM méretét a gép méretével tudjuk átállítani, felfelé és lefelé egyaránt. A gép méretével arányosan növekszik a memória mérete is, az indulva az XS-es gép 768MB-tol indulva az XL-gépig minden lépésben 2x-ezve a memória méretét.
A memória és a CPU méretekbol egyébként így már egyszeruen következtethetjük, hogy mekkora hardverekkel operált az eredeti Azure kialakítás: az XL gép 8 CPU magot és 14 GB RAM-ot tartalmazott, amibol ismét nem nagy titok derül ki ha azt mondom hogy egy elso Azure fizikai kiszolgáló tehát 8 CPU maggal és 16 GB RAM-mal rendelkezett. Ezen a vason futhatott vagy egy XL, vagy két L vagy négy M vagy nyolc S vagy húsz XS gép. A „maradék” hardver kapacitásokat természetesen a host OS és management eroforrás igények viszik el.
Az A6 és A7 géptípusok megjelenésébol láthatjuk, hogy az adatközpontokban megkezdodött egy új generációs hardverek beszerzése, amik nagyobb virtuális gép suruséget engednek meg. Az A6-os gép (4 CPU core 28 GB RAM) és az A7-es gép (8 CPU core és 56 GB RAM) kifejezettem a memória intenzív workloadok végett került bevezetésre. Az A6 és A7 gépek csak akkor választhatóak, ha olyan fabric cluster-ben van a cloud service-ünk ami már támogatja ezeket a gép méreteket is.
Hálózat
A hálózati sávszélesség teljesítménye kapcsán eloször értsük meg hogy hogyan kapcsolódnak a hálózathoz az Azure virtuális gépek. A virtuális gép minden esetben az Azure adatközponton belüli virtualizált hálózathoz kapcsolódik, akár definiáltunk saját virtual network-öt akár nem. Elöször is értsük meg a hálózati topológát, amire összeraktam ezt a sematikus ábrát:
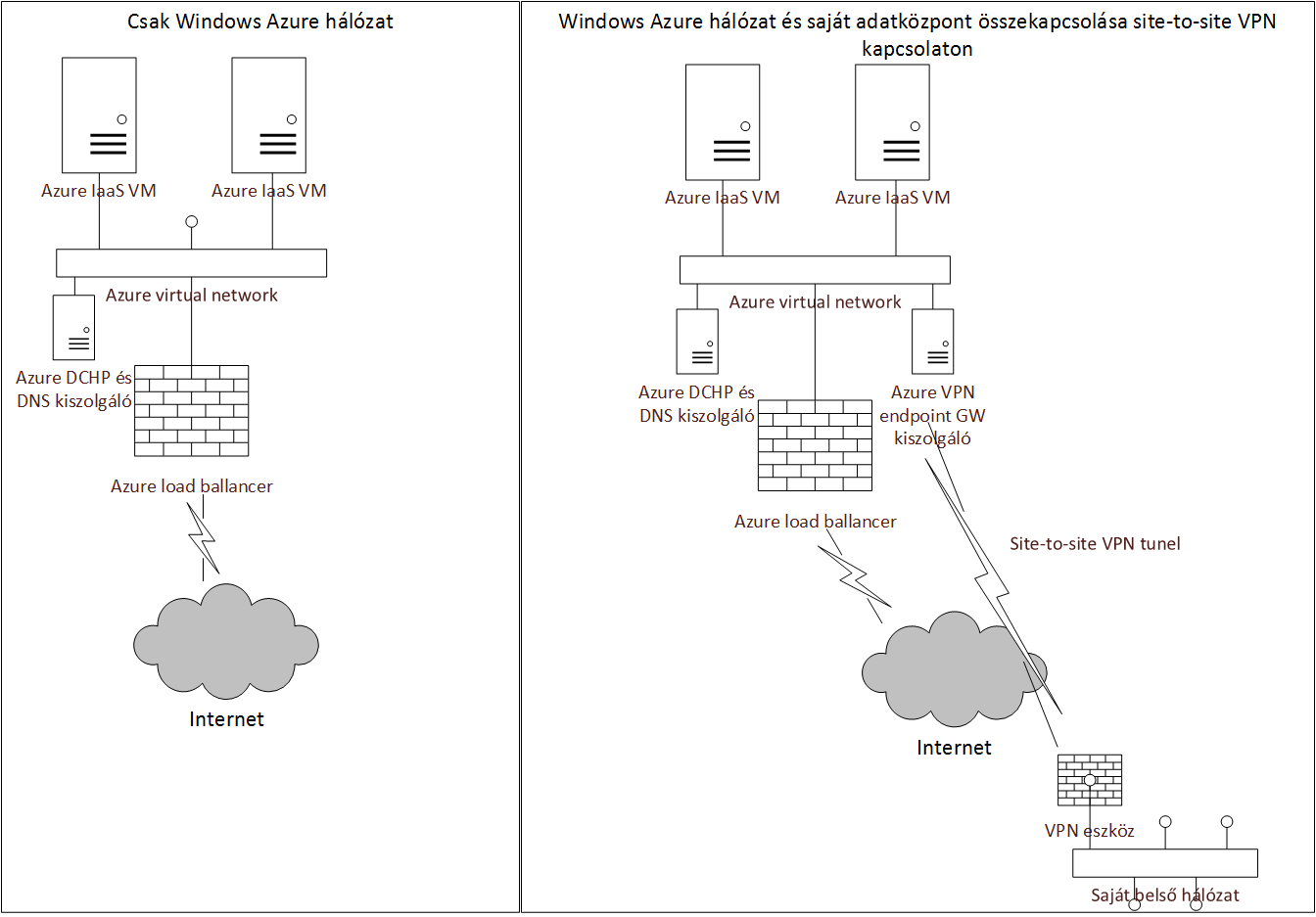
Vagyis az Azure hálózatot az alábbiak jellemzik:
- Minden virtuáis gép csak és kizárólag egy interfésszel rendelkezik
- Az Azure gépek közötti, az Azure gép és internet közötti és az Azure gép és saját adatközpont közötti hálózati forgalom is ezen az interfészen keresztül történik
Tehát ha az Azure gép esetében valamilyen hálózati irányban lassúságot tapasztalunk, akkor azt érdemes ellenorizni, hogy a gép milyen irányú kommunikációt végez még (pl.: az internetrol elérheto Azure-ban futó web front-endeket a VPN kapcsolaton keresztül a belso hálózatról lassú válaszidovel érem el akkor eloször azt kell megnéznünk hogy nem az internet, felöli forgalom vagy az Azure VM-ek közötti forgalom miatt van-e hálózati szuk keresztmetszetem.
Az elso táblázatban levo sávszlesség információkat idoközben levettük a nyilvános Azure oldalakról, ennek oka pedig az, hogy megtéveszto és félre értheto. Értsük meg a szándékot mögötte: Az Azure VM-ek fizikai gépeken futnak, amik limitált sávszélességgel rendelkeznek, és a virtuális gépeknek amik rajta futnak ezen kell osztozniuk amellett hogy biztosítják a kommunikációs lehetoséget a host számára is. Csakhogy nem mindegy hogy a gép milyen irányba kommunikál, hiszen ha egy másik virtuális géppel ami ugyan azon a host-on van akkor az a „hálózati” kommunikáció tulajdon képen egy memórián belüli kommunikáció, ami nem kerül ki a hálózati kártyára vagy a fizikai hálózatra. Ezért ezeket a forgalmakat nem is érdemes korlátoznia a guest agent-nek. A guest agent tehát csak a valós hálózatra kerülo forgalmakat kell hogy korlátozza és a legjobb tudomásom szerint ott még léteznek a fenti táblázat beli limitek, bár a hardver cserék és bovítésekkel ez is változhat. Mindenesetre tartsuk észben a fenti limiteket ha arra gyanakszunk hogy ez a szuk keresztmetszet akkor a szerint gondoljuk végig a lehetséges lépéseket.
Ami az internete elérést szintén ezen a vonalon keresztül történik és itt is a VM jelentheti legfeljebb a limitet. Ami a site-to-site VPN-t illeti minden subnet egy dedikált VPN végpont virtuális gépet kap ami biztosítja a megfelelo sávszélességet (amikor a VPN-ért fizetünk akkor tulajdonképpen ezért a „router” virtuális gépért fizetünk). A S2S VPN esetén természetesen a „ minden lánc olyan eros amilyen a leggyengébb láncsszem” elv érvényesül, a sávszélesség és a késleltetés tekintetében. Amire a S2S VPN-nél fontos még oda figyelni: nem a „standard” MTU méretet használja a konfiguráció ezért mindenképp kövessük a hivatalos leírást, használjuk a támogatott VPN eszközöket és az ezekhez az eszközökhöz tartozó konfigurációs script-eket: https://msdn.microsoft.com/en-us/library/windowsazure/jj156075.aspx
A tapasztalatom szerint az MTU méret több eszköz esetén „globális” beállítás ami minden VPN kapcsolatra kihatással van, ezért gondoljuk végig melyik eszközt akarjuk az Azure IaaS S2S VPN kapcsolat felépítésére használni. Esetleg használhatunk egy Windows Server 2012 vagy újabb gépen futó Routing and Remote Access kiszolgálót is, ehhez is megtalálhatóak a fenti linken a konfigurációs script-ek.
Diszk
A diszk teljesítmény esetén a legfontosabb hogy megértsük az Azure IaaS muködését. Az Azure (Red Dog) eredetileg PaaS szolgáltatások kiszolgálására lett tervezve, vagyis olyan alkalmazásokra amelyek kifjeezetten az Azure blob storage adattárolási jellegzetességeire építenek. Az IaaS ebbol fejlodött ki. A virtulis gépünk az alábbi diszkekbol épül fel:
| Betujel | Hol helyezkedik el | Megjegyzés |
| C: | Azure blob storage | 127 GB kapacitás, OS és alap fájloknak. Nem javasolt adattárolásra használni |
| D: | on fizikai gép diszkjén ahol a VM éppen fut | Ideiglenes terület, ami a gép újraindításakor elveszhet |
| További diszekek | Azure blob storage | Állandó diszkek, ezeket javasolt alkalmazás telepítésre, adattárolásra használni |
A további diszkek számát meghatározza hogy milyen méretu Azure VM-et használunk. Egy disk mérete legfeljebb 1 TB lehet (tehát a legnagyobb tároló kapacitás XL gép alatt lehet legfeljebb 16TB méretben. Mint a táblázatból látszik, a D: egy olyan diszk ami azon a fizikai gépen helyezkedik el amin a VM éppen fut. Ebbol következik, hogy itt az elérési ido attól függ hogy a többi gépe amin fut még azon a fizikai gépen mennyire használja ezt a diszket. Viszont nagyon nagy hátránya ennek hogy ha a VM költözik az itt tárolt adatok elvesznek. Ez ideálissá teszi TEMP dirve-nak (gyors, de a tartalma újra indítás után elveszhet), hiszen erre is lett létrehozva a PaaS világban.
Az állandó (perzisztens) diszkek Azure blob storage-ben helyezkednek el, vagyis mindegy hogy milyen fizikai gépen fut a VM-ünk ennek a tartalmát mindig látja. Az Azure-ban három kiszolgáló típus létezik: Compute (VM-ek futtatása akár IaaS akár PaaS), storage (ezek adják a blob storage kapacitást) és SQL (a PaaS SQL-hez). Tehát látható hogy az adattárolást nem high-end és high performance storage-k adják (hiszen az nem lenne jól skálázható, sem költség hatékony), hanem fizikai kiszolgálókban futó diszkekbol van kialakítva az adattároló kapacitás. Ezért amikor azt mondjuk, hogy az adat legalább egy adatközponton belül három helyen megvan akkor az azt jelenti hogy három különbözo blob storage kiszolgáló diszkén van jelen, illetve georedundáns kialakítás esetén hat gépen (adatközpontonként 3-3).
Az Azure compute node-ok tehát minden egyes VM futtatásánál a diszk IO muveleteket is hálózaton kell hogy továbbítsák az Azure blob storage kiszolgálók felé. Ez nyilván teljesítményben és válaszidoben nem olyan mintha lokális vagy high-end storage kapacitásból kerülne kiszolgálásra, ezt mindenesetben vegyük figyelembe az Azure-ra költöztetendo workload-ok tekintetében.
Az Azure csapat nem közöl hivatalos számokat a disz IO performanciáról (vagy legalábbis én még nem találtam meg), amivel tudunk javítani az alábbiak lehetnek:
Cache
Disk cache használata: ez lehet Read-only vagy Read-Write cache is. Ez esetben a cache a VM-et futtató fizikai gép memóriájában történik a cache-lés, vagyis amennyiben fontos a diszk konzisztencia abban az esetne is, ha a fizikai kiszolgáló megáll a gépünk alatt és a VM-ünk másik gépre költözik akkor ne használjunk legfeljebb Read-only cache-t. Minden más esetben az a tény hogy az egyszer kikért adatokat a lokális memóriából kapja meg a VM és nem kell átmennie a host gépen, aki kikéri az adatot a blob storage kiszolgálóról az jelentosen tud javítani a teljesítményen.
A cache-lés egy másik érdekes alternatívája az hogy az Azure igyekszik az adatokat a felhasználáshoz legközelebb elhelyezni. Ez az jelenti, hogy miután egy gépet létrehoztunk a disk-jeit az Azrue igyekszik olyan blob storage kiszolgálókra költöztetni, ami fizikailag (hálózatilag) a leheto legközelebb van a VM-ünket futtató compute node-hoz. Ezért tapasztalhatjuk azt hogy a frissen létrehozott VM-ünk sokkal lassabb mint egy vagy két nap múlva ha rátekintünk (nem csak érzésre, de perfomon mérésre is)
RAID 0
A RAID 0 vagyis stripe olyan dolog, amit alapból elvet az agyunk, mondván jó hogy növeli a teljesítményt, de egy diszk kiesésével bukom az egész kötet tartalmát. Viszont mint írtam az Azure esetében minden VHD fájl legalább három blob storage kiszolgálón van meg, vagyis a Microsoft gondoskodik arról hogy a VM-em alatt levo VHD sose vesszen el. Így egybol nem olyan ördögtol való gondolat hogy a VM-hez csatlakoztassal több VHD-t és azokat a Windows lemezkezelojével összefuzzem egy RAID 0 (stripe) kötetté. Mivel a VHD fájlok elérése párhozamosan történik, ezért ezzel tudok nyerni a teljesítményen.
Vagyis tegyük fel hogy egy „M” méretu gépben szükségem van 1 TB tárkapacitásra. Ez esetben az 1 darab 1 TB-os diszk helyett teljesítmény szempontból jobban járok ha az 1 TB tárkapacitást 4 darab (ez a max diszk szám „M” gép esetén) 250 GB-s diszkbol rakom össze.
Teljesítmény mérés
Végezetül visszatérve az eredeti kérdésre: hogyan mérjünk performanciát az Azure gépek esetén? Pont ugyan úgy mint ahogy azt eddig tettük, perfomon és egyéb eszközök a barátaink, ugyan azokat a count-ereket érdemes figyelnünk, hozzátéve azt hogy tudjuk és értjük hogy muködnek a VM-ek az Azure-ban.
Kifejezetten SQL workload-ok futtatására van egy whitepaperünk is publikálva: „Performance Guidance for SQL Server in Windows Azure Virtual Machines”