Software Reigns in Microsoft’s Cloud-Scale Datacenters
 David Gauthier, Director
David Gauthier, Director
Datacenter Architecture & Design
Operating and maintaining the infrastructure behind Microsoft's huge cloud is a mission critical endeavor. With over 200 cloud services, including Bing, Office 365, Skype, SkyDrive, Xbox Live, and the Windows Azure platform running in our data centers, the Global Foundation Services' (GFS) team is a key component in delivering the highly available experience our customers expect from the cloud. To do this effectively, we're continuously evolving our operational strategies to drive quality and efficiency up while lowering costs and increasing overall value to our customers. Through this process, we've adopted an uncommon approach to designing, building, and operating our data centers - rather than focusing on hyper-redundant hardware, we prefer to solve the availability equation in software. In doing so, we can look at every aspect of the physical environment - from the server design to the building itself - as a systems integration exercise where we can create compounding improvements in reliability, scalability, efficiency, and sustainability across our cloud portfolio. (See new Cloud-Scale videos and strategy brief).

Microsoft's cloud serves 1+ billion customers and 20+ million businesses in 76+ markets.
In my role as director of Datacenter Architecture for GFS, I lead the technical strategy and direction of our global data center footprint. I get to spend a lot of time working on the integration of cloud software platforms with the underlying hardware, automation, and operational processes. Operating one of the world's largest data center portfolios provides us tremendous experience and we're continually leveraging new insights and lessons learned to optimize our cloud-scale infrastructure. In this post, I'd like to share more about how cloud workloads have changed the way we design and operate data centers, and software's role in this evolution.
A Radical Shift to Cloud-Scale
Since opening our first data center in 1989, we've invested over $15 billion to build a globally distributed datacenter infrastructure. As recently as 2008, like much of the industry, we followed a traditional enterprise IT approach to data center design and operation. We built highly available online services sitting on top of highly available hardware with multiple levels of redundant and hot-swappable components. The software developer could effectively treat the hardware as always available and we made capital investments in redundancy to protect against any imaginable physical failure condition.
This early enterprise IT approach to redundancy has proven successful for many organizations and it definitely enabled us to deliver highly available services. By 2009, however, millions of new cloud service's users were moving to our cloud and the Microsoft cloud had to quickly scale out. It became clear that the complexity and cost required to stay the traditional industry course would quickly become untenable. Additionally, simply 'trusting' in hardware redundancy distracted focus from the one of the biggest issues that affect even the best engineered datacenter - humans.
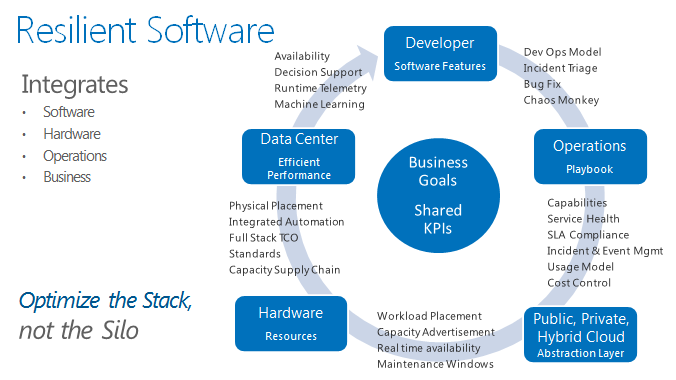
At Microsoft, we're following a different model focused on shared business goals and common performance indicators. The physical infrastructure is engineered to provide various resource abstraction pools - such as compute and storage - that have been optimized against total-cost-of-ownership (TCO) and time-to-recover (TTR) availability models. These abstractions are advertised as cloud services and can be consumed as capabilities with availability attributes. Developers are incented to excel against constraints in latency, instance availability, and workload cost performance. Across groups, development operations teams participate in day-to-day incident triage, bug fixes and disaster scenario testing to identify and remediate potential weak points.
Events, processes, and telemetry are automated and integrated through the whole stack - data center, network, server, operations, and application - to inform future software development activities. Data analytics provides us decision support through runtime telemetry and machine learning that completes a feedback loop to the software developers, helping them write better code to keep service availability high.
Of course, software isn't infallible, but it is much easier and faster to simulate and make changes in software than physical hardware. Every software revision cycle is an opportunity to improve the performance and reliability of infrastructure. The telemetry and tools available today to debug software are significantly more advanced than even the best data center commissioning program or standard operating procedure. Software error handling routines can resolve an issue far faster than a human with a crash cart. For example, during a major storm, algorithms could decide to migrate users to another data center because it is less expensive than starting the emergency back-up generators.

What about the Hardware?
This shift offers an inflection point to reexamine how data centers are designed and operated where software resiliency can be leveraged to improve scalability, efficiency, and costs, while simplifying the datacenter. But of course, there is a LOT of hardware in a cloud-scale datacenter.
In our facilities, the focus shifts to smarter physical placement of the hardware against less redundant infrastructure. We define physical and logical failure domains, managing hardware against a full-stack total cost of ownership (TCO) and total time to recover (TTR) model. We consider more than just cost per megawatt or transactions per second, measuring end-to-end performance per dollar per watt. We look to maintain high availability of the service while making economic decisions around the hardware that is acquired to run them. So while these services are being delivered in a mission critical fashion, in many cases the hardware underneath is decidedly not mission critical. I'll share some more details on the design of our physical datacenter infrastructure in a future post, but the short story is 'keep it simple'.
In moving to a model where resiliency is engineered into the service, we can not only make dramatic architectural and design decisions to improve reliability, scalability, efficiency, and sustainability, we also ensure better availability to the customer. This is our ultimate goal. We're at an exciting point in our journey and as we drive new research and new approaches, we look forward to sharing more of our experiences and lessons. In the meantime, please take look at our Microsoft Cloud-Scale data center page with new videos and a strategy brief on the topic.
//dg
- David Gauthier, Director, Datacenter Architecture & Design