VSS Timeouts during Backup? Check Fragmentation!
Volume Snapshot Services (VSS) was and remains a good addition to the Windows OS. Without going into a lot of detail, this technology coordinates various components to ensure stable point-in-time backups even while applications may be running. Typically, this occurs successfully with only minimal interruption to the application. On occasion there can be problems taking backups of systems that result from configuration issues, missing fixes, to third-party providers and writers that need updates. VSS really does a lot during the course of a normal backup. There are a couple of points during the process that actions must be timely. Failure of components to complete I/O within the allotted time results in timeout. Sometimes something as simple as file system fragmentation can be the reason behind such timeouts.
A really good link describing all the things that happen during a VSS backup may be found using the following link.
https://msdn.microsoft.com/en-us/library/aa384589(v=VS.85).aspx
Using the above link you will find a chart of VSS activities. Common places for trouble in this process are the shaded green and red areas. Consider the below excerpt from the chart:
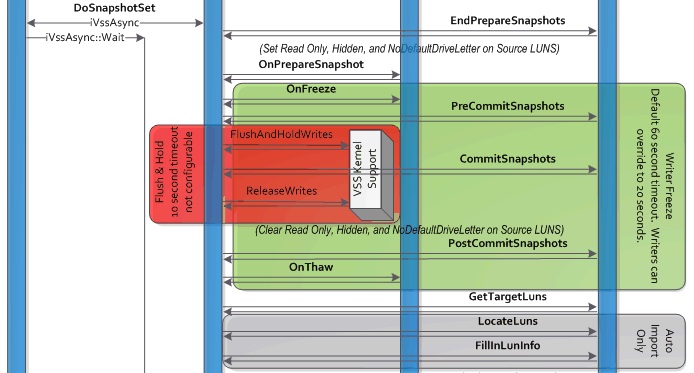
Each of these two highlighted areas denotes the finite amount of time for which operations must complete to avoid timeout. One particular configuration issue that can cause timeouts and backup failures at this juncture is file system fragmentation. Sounds pretty trivial right? Sure. For most systems and most environments a defragmentation plan may exist to prevent issues and to ensure optimum performance. In fact, many clients have a scheduled task to defrag the system drive automatically. In the case where the volume isn’t defragmented regularly and there are no other combined issues, running defrag.exe may resolve the condition quickly to allow successful backups. However, if you have a file system that was upgraded from an older operating system – or by chance was formatted using an older deployment tool – it is possible that the file system may be using a smaller cluster size and may be more prone to ragmentation than the average system that uses a default cluster size or larger. It is also possible that systems like this may have other contributing factors that may prevent defrag.exe from resolving the issue of fragmentation preventing successful backups. It is recommended that systems use the default cluster size or larger for best performance.
Background on Converted Volumes and Small Cluster Size
If you find that a system volume has a small cluster size of 512 bytes (not to be confused with the sector size which is commonly 512 bytes), this file system might have been converted to NTFS at one point in the past by CONVERT.EXE. FAT could be the original file system later converted to NTFS. It is known that when converting to NTFS with CONVERT.EXE, the cluster size does not change from the original file system. Perhaps this system was upgraded to Windows Server 2003 or may have been formatted with some other type of deployment utility that used a small cluster size. When a volume is formatted freshly with NTFS, the file system uses a default cluster size of 4K providing the volume is less than 16TB. Volumes with a small cluster size are more likely to achieve significant levels of fragmentation faster than a volume of same size using a default or larger cluster size. Therefore, volumes with small cluster sizes may require more frequent defragmentation.
A second characteristic that may contribute to fragmentation is lack of free space. As a volume gets closer to being full, the likelihood of fragmentation increases. Combine this characteristic with a small cluster size and the likelihood of a highly fragmented volume increases dramatically.
A third contributing characteristic would be if the volume contains a page file configured to allow dynamic expansion as needed. If the page file experiences frequent extension on a volume that is already highly fragmented, the page file may become highly fragmented as well. A highly fragmented page file not only impacts performance but also may impede the ability to defragment the volume…especially if the volume is more than 60%-70% full.
The additional head and platter movements required because of the degree of fragmentation can easily result in VSS timeout because I/O operations have to be split into multiple I/O requests to retrieve data. Depending on the degree of fragmentation coupled with contributing factors may present a situation that defag.exe can’t easily resolve in order to complete a successful backup.
Mitigation of a Highly Fragmented Volume that Won’t Defragment
I recently consulted on a case where the page file itself contained over 500,000 fragments on a volume that was fragmented. For this volume, defragmentation activities could not get fragmentation on the volume below 20% and the delays to VSS consistently prevented successful backups. To resolve this condition in order to conduct a successful backup, the page file had to be removed from the system volume and located elsewhere, a restart performed, and defrag allowed to run a few times. Then after successful defrag and backup, we set the page file on the system volume to be a fixed size and sufficient for the system. The restart in this sequence of events is important because some file system space may remain locked after setting the page file on the system volume to zero. In fact, it might be better to approach this with a defragmentation utility being run from WinPE or safe mode so that the list of potential obstacles is even shorter.
The problem experienced on this system was one of cyclical nature contributed to by small cluster size, reduced amount of free space, and a dynamically expanding page file. Running defrag on a more frequent basis, removing page file issues, and keeping sufficient free space can prevent this type of situation from recurrence. Removing any one of the key issues would have had a positive impact on preventing the situation. However, the potential for fragmentation and VSS issues continues due to the small cluster size in use.
Typically for a system disk, the 4K default cluster size is adequate. For a volume to hold only databases you would likely use a much larger cluster size for better efficiency as recommended by the application. On any systems like this one that remain in production, it is advisable to monitor and address fragmentation on a regular basis to avoid issues. It may be desirable to negotiate down time to reformat the system volume with a larger cluster size and restore a known good backup to alleviate potential recurrence of issues and reduce the extra administrative overhead for a system using a small cluster size for the file system.
Determining the Cluster Size
It may be a good proactive step to check other 2003 servers for 512 byte cluster sizes on the system partition in an effort to increase awareness of volume and page file fragmentation and to adjust practices as needed. An easy command to display cluster size is as follows:
fsutil fsinfo ntfsinfo c:
Sample output from a 512 byte cluster size volume:
.
.
.
Bytes Per Sector : 512
Bytes Per Cluster: 512 <
Sample output from a 4096 byte (4K) cluster size volume:
.
.
.
Bytes Per Cluster : 4096 <
Additional Considerations
If using volumes with a small cluster size and using Shadow Copies for Shared Folders to have previous versions of files available, the number of changes caused by defragmentation on a highly fragmented volume can also cause shadow copies containing previous versions of files to be deleted. Therefore, for Shadow Copies for Shared Folders, it is a best practice to use 16K clusters or larger.
For more information about NTFS, please consult the following TechNet document: