Exchange 2010 でのデータベース保守
原文の記事の投稿日: 2011 年 12 月 14 日 (水曜日)
ここ数か月、Exchange 2010 データベースのバックグラウンド データベース保守とはなにか、それがなぜ重要かについて多くの質問がありました。この記事では、これらの質問にお答えします。
データベースにどのような保守タスクを行う必要があるか
Exchange データベースには、以下のタスクを定期的に行う必要があります。
データベースの圧縮
データベース圧縮の主要な目的は、データベース ファイルで未使用の領域を解放することです (しかし、これにより、未使用の領域がファイル システムに戻されるわけではないということは注意する必要があります)。この操作の意図は、可能な限り最少のページ数にレコードを圧縮することによってデータベース内のページを開放し、結果として必要な IO の量を減らすことです。ESE データベース エンジンは、データベース内のテーブルを記述する情報であるデータベース メタデータを取得して、各テーブルについてテーブル内のページを参照し、論理的に並べ替えられたページにレコードを移動することを試行します。
データベース ファイルのフットプリントを最小限に維持するには、以下を含め、いくつかの重要な理由があります。
- データベース ファイルのバックアップにかかる時間を減らす
- データベース ファイルを予測可能なサイズに維持する。サーバー/記憶域の規模設定に重要
Exchange 2010 より前は、データベース圧縮処理は、オンライン保守ウィンドウで行われていました。この処理では、データベース内の複数ページ間でレコードを並べ替えたことから、ランダムな IO が生成されていました。この処理は、以前のバージョンでは十分に役立っていました。データベース ページを開放して、レコードを並べ替えることにより、ページは常にランダムな順になっていました。ストア スキーマ アーキテクチャと同時に使われることで、これにより、(フォルダーにアイテムをダウンロードするような) 一連のデータを取得するすべての要求で、常にランダムな IO が発生していました。
Exchange 2010 では、領域圧縮より隣接性が優先されるように、データベース圧縮が再設計されました。さらに、データベース圧縮がオンライン保守ウィンドウから移動され、連続的に実行されるバックグラウンド プロセスになりました。
データベース最適化
データベース最適化は、Exchange 2010 の新機能で、OLD v2 および B+ ツリー最適化とも呼ばれます。この機能は、順次であるとヒント、またはマークが付けられたデータベース テーブルを圧縮し最適化する (順次的にする) ことです。データベース最適化は、順次的とマークの付けられたテーブルの圧縮を維持することに加え、時間が経過してもディスク リソースの効率的な使用を維持する (IO がランダムにならず順次的になるようにする) 目的で重要です。
データベース最適化プロセスは、行う処理があるか判定する目的でその他のデータベース ページ処理を監視するモニターと考えることができます。空いたページがあるかすべてのテーブルを監視し、一定のしきい値に達した場合、つまりテーブルでの合計 B+ ツリー ページ カウントが高い割合で空いた場合に、空いたページをルートに返します。また、順次的な領域ヒントを含むテーブル セット (既知の順次的利用状況パターンで作成されたテーブル) 内で隣接性を維持する目的で機能します。データベース最適化が、順次的テーブル上にスキャン/事前読み取りを検出し、レコードがテーブル内で順次的なページに保存されていない場合は、プロセスは、問題があるすべてのページを B+ ツリー内の新しいエクステントに移動することにより、テーブルのそのセクションを最適化します。パフォーマンス カウンターを使用して (監視のセクションを参照)、安定した状態に達した後は、データベース最適化はほとんど実行されないことを確認できます。
データベース最適化は、処理が行われるときに連続的にデータベースを分析し、必要に応じて非同期作業を開始するバックグラウンド プロセスです。データベース最適化は、以下の 2 つのシナリオで調整されます。
- 未処理のタスクの最大数これにより、データベースに対して大規模な変更が行われたとき、最初の処理でデータベース最適化をし過ぎないようできます。
- 100 ms の待機時間調整 システムが過負荷になったとき、データベース最適化の処理は中断されます。中断された処理は、データベースが、次回、同じ処理パターンになったときに実行されます。最適化処理が中断された形跡は残らず、システムのリソースが十分になったときに、再度、実行されます。
データベースのチェックサム確認
データベース チェックサム確認は、 オンライン データベース スキャンとも呼ばれ、データベースが大規模なチャンクで読み取られ、(物理的ページ破壊がないか) 各ページがチェックサム確認されるプロセスです。チェックサム確認の主要な目的は、トランザクション処理によって検出されない物理的な破壊と失われたフラッシュを検出することです (古いページ)。
Exchange 2007 RTM とすべての以前のバージョンでは、チェックサム確認処理は、バックアップ プロセス中に行われていました。チェックサム確認される唯一のデータベースが、バックアップ処理対象のデータベースであったことから、これは複製データベースでは問題となりました。パッシブ データベースがバックアップされるシナリオでは、アクティブ データベースがチェックサム確認されないことになります。このことから、Exchange 2007 SP1 で、新しいオプションのオンライン保守タスク、オンライン保守チェックサム確認を導入しました (詳細は、「Exchange 2007 SP1 ESE Changes – Part 2 (英語)」を参照)。
Exchange 2010 では、データベース スキャンがデータベースをチェックサム確認して、ポスト Exchange 2010 ストア クラッシュ処理を行います。領域はクラッシュによってリークされることがあり、オンライン データベース スキャンは失われた領域を見つけて、復旧します。データベース チェックサムは、256KB の IO をアクティブに使用して、データベース (アクティブとパッシブの両方) をスキャンし、それぞれを毎秒約 5 MB で読み取ります。IO は 100 % 順次的です。Exchange 2010 のシステムは、すべてのデータベースが 7 日ごとに完全にスキャンされるという想定で設計されています。
スキャンに 7 日より長くかかる場合、以下のイベントがアプリケーション ログに記録されます。
イベント ID: 733
イベントの種類: 情報
イベント ソース: ESE
詳細: インフォメーション ストア (15964) MDB01: オンライン保守によるデータベース 'd:\mdb\mdb01.edb' に対するデータベース チェックサムのバックグラウンド作業が、時間内に完了していません。この処理は 2011/10/11 に開始され、(7 日間で) 604800 秒間実行されています。
アクティブなデータベースでのスキャンが 7 日間より長くかかる場合は、スキャンが完了した後で、アプリケーション ログに以下のエントリが記録されます。
イベント ID: 735
イベントの種類: 情報
イベント ソース: ESE
詳細: インフォメーション ストア (15964) MDB01 データベース保守はデータベース 'd:\mdb\mdb01.edb' でのフル パスを完了しました。このパスは 2011/10/11 に開始して、合計 777600 秒の間、実行されました。このデータベース保守タスクは、7 日間の保守完了しきい値を超過しました。以下の 1 つ以上の作業を行う必要があります。データベースをホストしているボリュームの IO パフォーマンス/スループットを上げる、データベースサイズを減らす、非データベース保守 IO を減らす。
さらに、7 日間で完了しない場合は、途中警告がアプリケーション ログに記録されます。
Exchange 2010 では、アクティブなデータベースにデータベース チェックサム確認を実行する際に、2 つのモードがあります。
- 週 7 日、24 時間、バックグラウンドで実行これは既定の動作です。すべてのデータベース、特に 1 TB より大きなデータベースではこれを使用する必要があります。Exchange は、毎日、最大で 1 度、データベースをスキャンします。読み取り IO は (ディスクへの負担が軽くなる) 100% 順次的で、ほとんどのシステムでは約 5MB/ 秒のスキャン速度になります。スキャン プロセスは単一スレッドで、IO 待機時間によって調整されます。待機時間が増えると、ページの新たなバッチ スキャンを実行するまで (一度に 8 ページが読み取られます)、データベース チェックサム確認に時間がかかるようになります。最後のバッチが完了するまで、より長く待機中になるからです。
- スケジュール設定されたメールボックス データベース保守プロセスで実行 このオプションを選択すると、データベース チェックサム確認は最後のタスクになります。どれだけの時間、実行するかは、メールボックス データベース保守スケジュールを変更することで構成できます。このオプションは、完全なスキャンの完了にかかる時間が少ない、1 TB 未満の小規模なデータベースに限って使用する必要があります。
データベースの規模にかかわらず、推奨されるのは、既定の動作を使用することであり、アクティブなデータベースに対してスケジュール設定されたプロセスとしてデータベース チェックサム処理を構成しないことです (つまり、オンライン保守ウィンドウでプロセスとして構成しないでください)。
パッシブ データベースでは、データベース チェックサム確認は実行時に行われ、バックグラウンドで連続的に処理されます。
ページへの更新プログラム適用
ページへの更新プログラム適用は、破損ページを正常なページで置換するプロセスです。以前に説明したように、破損ページの検出はデータベース チェックサム確認の機能です (さらに、破損ページは、実行時にも、ページがデータベース キャッシュに保存されるときに検出されます)。ページへの更新プログラム適用は、高可用性 (HA) データベースに悪影響を及ぼします。破損ページが修復される方法は、HA データベースがアクティブか、またはパッシブかにより異なります。
ページへの更新プログラム適用プロセス
| アクティブ データベースで | パッシブ データベースで |
|
|
ページの解放
データベースのページの解放は、セキュリティ処置として、データベース内の削除済みページを、パターン (ゼロ) で上書きするプロセスです。これにより、削除済みデータが不正な手段で利用されることを防げます。
Exchange 2007 RTM 以前のすべてのバージョンでは、ページの解放処理はストリーミング バックアップ プロセス中に行われていました。また、ページの解放処理は、ストリーミング バックアップ プロセス中に行われていたことから、ログに記録されませんでした (つまり、ページの解放はログ ファイルを生成しませんでした)。この結果、パッシブ データベースではページが解放されず、アクティブ データベースではストリーミング バックアップを行ったときのみページが解放されていたことにより、複製データベースでは問題となっていました。このことから、Exchange 2007 SP1 で、新しいオプションのオンライン保守タスク、チェックサム確認中のページの解放を導入しました (詳細は、「Exchange 2007 SP1 ESE Changes – Part 2 (英語)」を参照)。このタスクを有効にすると、オンライン保守ウィンドウ中にページを解放し、変更をログに記録してパッシブ データベースに複製します。
Exchange 2007 SP1 実装では、スケジュール設定された保守ウィンドウ中に解放プロセスが行われていたことから、ページが削除されたときから解放されるまでに、長い時間がかかっていました。このことから、Exchange 2010 SP1 では、ページ解放タスクは、ハード削除が行われたとき、一般的にはトランザクション時にページを解放する、連続的に動作する実行時イベントになりました。
さらに、データベース ページは、オンライン チェックサム確認プロセス中に取り消すことができます。この場合に対象となるページは以下のとおりです。
- (システムが過負荷の場合に) 除外されたタスク、または、タスクがデータを取り消す前にストアが停止したことにより、実行時中に取り消すことができなかった削除レコード
- 削除されたテーブルと 2 次的なインデックス。これらが削除されたときは、積極的にそのコンテンツを取り消すことはされません。オンライン チェックサム確認が、これらのページがどの有効なオブジェクトにも所属していないことを検出することで、取り消しがされます。
Exchange 2010 でのページ解放の詳細については、「Exchange 2010 のページの解放について」を参照してください。
これらのタスクがなぜスケジュール設定された保守ウィンドウ中に行われないのか
ページ解放、データベース最適化、データベース圧縮、オンライン チェックサム処理で、スケジュール設定された保守ウィンドウを使用することには、以下を含む重大な問題があります。
- スケジュール設定した保守操作をすることは、週 7 日、24 時間稼働するデータ センターの管理を非常に困難にします。このようなデータ センターは、さまざまなタイム ゾーンでのメールボックスをホストしており、スケジュール設定された保守ウィンドウの時間は、わずかしか、またはまったくありません。以前のバージョンの Exchange でのデータベース圧縮には、調整メカニズムがなく、IO がほとんどランダムで、ユーザー エクスペリエンスを低下させていました。
- 低層記憶域 (たとえば 7.2K SATA/SAS) に展開された Exchange 2010 メールボックス データベースでは、保守ウィンドウ タスクを実行する ESEで使用可能な有効な IO 帯域幅が減っています。この結果、IO 待機時間が保守ウィンドウ中に増加することで、適切な一定時間内に保守作業が完了しなくなるという問題があります。
- JBOD の使用は、データ認証に関してデータベースにさらなる課題となります。RAID記憶域では、配列コントローラーが、特定のディスク グループをバックグラウンド スキャンして、不良ブロックを検出し、再配置することは一般的です。不良ブロックは、不良セクターとも呼ばれ、ディスク上の、恒久的な損傷によって使用できないブロックです (たとえばディスク パーティクルへの物理的な損傷)。また、配列コントローラーが、不良ブロックを初回読み取り要求で検出した場合は、代替のミラーリングされたディスクを読み取ることも一般的です。配列コントローラーは、そのとき、不良ブロックに "不良" というマークを付けて、新しいブロックにデータに書き込みます。これらのすべてが行われるときは、ディスク読み取りの待機時間がわずかに増加するだけで、アプリケーションは把握できません。RAID または配列コントローラーなしには、不良ブロックの検知と修復の両方とも行われません。RAID なしの場合、不良ブロックの検出と修復は、アプリケーション (ESE) しだいです (つまり、データベース チェックサム確認)。
- より大きなディスク上のより大きなデータベースでは、データベースの順次性/圧縮を維持する目的で、より長い保守期間を必要とします。
前述の問題点により、Exchange 2010 では、データベース保守タスクをスケジュール設定されたプロセスから移動し、実行時中にバックグラウンドで連続的に実行することが重要です。
これらのバックグラウンド タスクがエンド ユーザーに影響を与えないか
これらのバックグラウンド タスクは、データベースに対して行われる作業に基づいて自動的に調整されるように設計されています。さらに、メッセージプロ ファイルについての規模設定ガイダンスは、これらの保守タスクを考慮しています。しかし、記憶域アーキテクチャを設計するときは、注意する必要があります。同じ LUN またはボリューム上に、複数のデータベースを格納するよう計画している場合は、すべてのデータベースの合計サイズが 2 TB を超えないようにします。これは、データベース保守がデータベース/ボリュームの数に基づいてシリアル化することによって調整され、合計サイズが 2 TB 以下と想定しているからです。
これらのバックグラウンド保守タスクの有効性を監視する方法
Exchange の以前のバージョンでは、アプリケーション ログのイベントが、オンライン最適化のような処理を監視する目的で使用されていました。Exchange 2010 では、最適化および圧縮の保守タスクについては、イベントは記録されません。しかし、パフォーマンス カウンターを使用して、MSExchange Database ==> Instances オブジェクトでバックグラウンド保守タスクを追跡管理できます。
| カウンター | 説明 |
| データベース保守期間 | このデータベースの保守が開始してから経過した時間 (秒) |
| データベース保守ページ不良チェックサム | データベース保守パス中に発生した、修正不可能なページ チェックサムの数 |
| 最適化タスク | 現在、実行中のバックグラウンド データベース最適化タスクの数 |
| 完了した最適化タスク/秒 | 完了したバックグラウンド データベース最適化タスクの速度 |
以下のページ解放カウンターは、MSExchange Database オブジェクトの下にあります。
| カウンター | 説明 |
| 解放されたデータベース保守ページ | パフォーマンス カウンターが呼び出されてからデータベース エンジンによって解放されたページ数 |
| 解放されたデータベース保守ページ/秒 | ページがデータベース エンジンによって解放される速度 |
データベース内の空白領域を確認する方法
シェルを使用して、データベース内の空白領域を確認できます。メールボックス データベースでは、以下を使用します。
Get-MailboxDatabase MDB1 -Status | FL AvailableNewMailboxSpace
パブリック フォルダー データベースでは、以下を使用します。
Get-PublicFolderDatabase PFDB1 –Status | FL AvailableNewMailboxSpace
空白領域を再利用する方法
データベースで使用可能な空白領域があれば、それを再利用する方法が必要になります。
しばしば、ESEUTIL を使用してデータベースのオフライン最適化を実行するがよいと思われていることがあります。しかし、これは当社の推奨事項ではありません。オフライン最適化を実行するとき、まったく新しいデータベースを作成しますが、この新しいデータベースを作成する目的で実行された操作は、トランザクション ログに記録されません。また、新しいデータベースは新しいデータベース署名を持っています。これは、このデータベースに関連付けられたデータベース コピーが無効になるということを意味します。
大きな空白領域を含むデータベースがあり、通常の処理では再利用できない場合、当社の推奨事項は以下のとおりです。
- 新しいデータベースとそれに関連付けられたデータベース コピーを作成します。
- 新しいデータベースにすべてのメールボックスを移動します。
- 元のデータベースとそれに関連付けられたデータベース コピーを削除します。
用語の混乱
バックグラウンド データベース保守という用語は混乱を招くことがあります。前述のタスクのすべてが、集合的に、バックグラウンド データベース保守を構成します。しかし、シェル、EMC、および JetStress は、すべて、データベース チェックサム確認のことをバックグラウンド データベース保守と呼んでいます。これは、これらのツールを使用してその有効と無効を切り替えるとき、構成の対象となるものです。
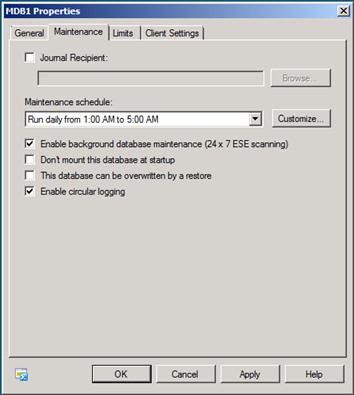
図 1: EMC を使用してデータベースのバックグラウンド データベース保守を有効にする
シェルを使用してバックグラウンド データベース保守を有効にする
Set-MailboxDatabase -Identity MDB1 -BackgroundDatabaseMaintenance $true
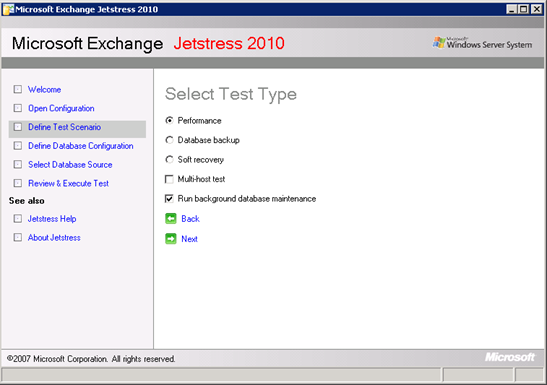
図 2: JetStress テストの一部としてバックグラウンド データベース保守を実行する
記憶域ベンダーがバックグラウンド保守タスクとしてのデータベース チェックサム確認を無効にするように推奨してきた場合
データベース チェックサム確認は、(順次的であっても) 記憶域が適切に設計されていない場合、IO に負担をかけます。これは、256 K 読み取り IO を行い、データベースごとに約 5 MB/s の IO を生成するからです。
記憶域ガイダンスの一部で、ストレージ配列ストライプ サイズ (配列内の各ディスクに作成されたストライプのサイズ。ブロック サイズとも呼ばれます) を 256 KB 以上に構成することを推奨しています。
JetStress で記憶域をテストし (英語)、データベース チェックサム処理がテスト パスに含まれていることを確認してください。
データベース チェックサム確認で、JetStress 実行が失敗した場合、いくつかのオプションがあります。
ストライピングを使用しない RAID-1 ペアまたは JBOD (アーキテクチャの変更が必要になることがあります) を使用し、Exchange 2010 の順次 IO パターンを活用します。
スケジュール設定する データベース チェックサム確認を、バックグラウンド プロセスではなく、スケジュール設定されたプロセスとして構成します。データベース チェックサムをバックグラウンド プロセスとして実装したとき、一部のストレージ配列は、順次読み取り IO を適切に処理できず、ランダム IO に最適化されている (または帯域幅の制限がある) ことは知られていました。それにより、この仕組みは無効にできるように設計されています (保守ウィンドウにチェックサム処理を移動する)。
この場合は、小規模のデータベースで行うことを推奨します。また、この場合でも、パッシブ データベースはデータベース チェックサムをバックグラウンド プロセスとして実行することに注意してください。つまり、記憶域アーキテクチャでこのスループットを考慮する必要があります。この件についての詳細は、「Jetstress 2010 and Background Database Maintenance (英語)」を参照してください。
異なる記憶域を使用するか、記憶域の機能を向上します Exchange のベスト プラクティス (256 KB 以上のストライプ サイズ) に適合する記憶域を選択します。
まとめ
Exchange Server 2010 でのデータベース エンジンのアーキテクチャの変更は飛躍的にパフォーマンスと安定性を向上しましたが、以前のバージョンからデータベース保守タスクの動作が変更されています。この記事で、Exchange 2010 でのバックグラウンド データベース保守とはなにか理解するお手伝いができれば幸いです。
Ross Smith IV
主席プログラム マネージャー
Exchange カスタマー エクスペリエンス
これはローカライズされたブログ投稿です。原文の記事は、「Database Maintenance in Exchange 2010」をご覧ください。