Maintenance de base de données dans Exchange 2010
Article d’origine publié le mercredi 14 décembre 2011
Au cours des derniers mois, plusieurs questions ont été posées sur la définition de la maintenance de la base de données en arrière-plan et son importance pour les bases de données Exchange 2010. Nous espérons que cet article répondra à ces questions.
Quelles tâches de maintenance faut-il effectuer sur la base de données ?
Les tâches suivantes doivent être exécutées régulièrement sur les bases de données Exchange :
- Compactage de la base de données
- Défragmentation de la base de données
- Contrôle de parité de la base de données
- Mise à jour corrective des pages
- Mise à zéro des pages
Compactage de la base de données
L’objectif principal du compactage est de libérer l’espace inutilisé au sein du fichier de base de données (cependant, notez que cette action ne restitue pas l’espace inutilisé au système de fichiers). Le but est de libérer les pages de la base de données en compactant les enregistrements sur le plus petit nombre de pages possible, ce qui permet de réduire le nombre d’E/S. Le moteur de base de données ESE exécute cette action en prenant les métadonnées (informations qui décrivent les tables de la base de données) et, pour chaque table, en visitant toutes les pages et en tentant de déplacer les enregistrements vers les pages classées logiquement.
La maintenance d’une empreinte de fichier d’une base de données épurée est importante pour plusieurs raisons, parmi lesquelles :
- Réduire le temps associé à la sauvegarde du fichier de base de données.
- Maintenir une taille de fichier de base de données prévisible, ce qui est important à des fins de dimensionnement du serveur/stockage.
Avant Exchange 2010, les opérations de compactage de base de données s’effectuaient lors de la période de maintenance en ligne. Ce processus entraînait des E/S aléatoires pendant le parcours de la base de données et la réorganisation des enregistrements à travers les pages. Ce processus était littéralement trop généreux dans les versions précédentes – en libérant les pages de base de données et en réorganisant les enregistrements, les pages se retrouvaient toujours dans un ordre aléatoire. Associée à l’architecture du schéma du magasin, toute demande d’extraction d’un ensemble de données (comme le téléchargement d’éléments d’un dossier) se traduisait toujours par des E/S aléatoires.
Dans Exchange 2010, le compactage de base de données a été refondu de telle sorte que la contiguïté soit privilégiée par rapport au compactage de l’espace. En outre, le compactage de la base de données a été retiré de la période de maintenance en ligne et constitue désormais un processus d’arrière-plan qui s’exécute en permanence.
Défragmentation de la base de données
La défragmentation de base de données est une nouvelle fonctionnalité d’Exchange 2010, également appelée défragmentation en ligne v2 et défragmentation de l’arborescence B+. Sa fonction est de compacter ainsi que de défragmenter (rendre séquentielles) les tables de base de données marquées/suggérées comme séquentielles. La défragmentation de base de données est importante pour maintenir une utilisation efficace des ressources disque au fil du temps (rendre les E/S plus séquentielles par opposition à aléatoires) et pour maintenir la présentation compacte des tables marquées comme séquentielles.
Vous pouvez assimiler la défragmentation de base de données à un processus qui surveille les autres opérations de base de données pour déterminer s’il y a un travail à faire. Le processus contrôle toutes les tables des pages libres, et si une table accède à un seuil où un haut pourcentage significatif du nombre total de pages de l’arborescence B+ est libre, il restitue les pages libres à la racine. Il fonctionne aussi pour maintenir la contigüité au sein d’un jeu de tables avec indications d’espaces séquentiels (table créée avec un modèle d’utilisation séquentielle connu). Si la défragmentation rencontre une analyse/prélecture sur une table séquentielle et que les enregistrements ne sont pas stockés sur les pages séquentielles de la table, le processus défragmente cette section de la table, en déplaçant la totalité des pages impactées vers une nouvelle extension de l’arborescence B+. Vous pouvez utiliser les compteurs de performance (mentionnés dans la section Analyse) pour vérifier la faible quantité de travail que la défragmentation de base de données effectue une fois qu’un état stable est atteint.
La défragmentation de base de données est un processus d’arrière-plan qui analyse en permanence la base de données au fur et à mesure que les opérations s’effectuent, puis déclenche l’opération asynchrone si nécessaire. La défragmentation de base de données est limitée par deux scénarios :
- Nombre maximal de tâches en suspens Cette limite empêche que la défragmentation n’effectue un travail trop important au premier passage si des modifications massives sont intervenues dans la base de données.
- Limite de latence de 100 ms Quand le système est surchargé, la défragmentation commence par reporter le travail de défragmentation. Le travail reporté sera effectué la prochaine fois où la base de données sera l’objet du même modèle opérationnel. Rien ne signale que le travail de défragmentation a été reporté et qu’il est exécuté une fois que le système a plus de ressources.
Contrôle de parité de la base de données
Le contrôle de parité de la base de données (aussi appelé analyse de base de données en ligne) désigne le processus où la base de données est lue par blocs et où chaque page est l’objet d’un contrôle de parité (détection de la corruption de page). L’objectif principal du contrôle de parité est de détecter la corruption physique et les vidages perdus qui peuvent ne pas avoir été détectées par les opérations transactionnelles (pages périmées).
Avec Exchange 2007 RTM et toutes les versions antérieures, les opérations de contrôle de parité se produisaient pendant le processus de sauvegarde. Il s’ensuivait un problème pour les bases de données répliquées, car la seule copie à être l’objet d’un contrôle de parité était celle en cours de sauvegarde. Pour le scénario où la copie passive était en cours de sauvegarde, cela signifiait que la copie active n’était pas l’objet d’un contrôle de parité. Aussi, dans Exchange 2007 SP1, avons-nous introduit une nouvelle tâche de maintenance en ligne facultative, Contrôle de parité de maintenance en ligne (pour plus d’informations, consultez Modifications du moteur ESE dans Exchange 2007 SP1 – Partie 2 (éventuellement en anglais)).
Dans Exchange 2010, l’analyse de la base de données contrôle la parité de la base de données et exécute des opérations de blocage de banque Exchange 2010. L’espace peut être perdu en raison des blocages et l’analyse de base de données en ligne récupère l’espace perdu. Le contrôle de parité lit environ 5 Mo par seconde pour chaque base de données en cours d’analyse active (copies actives et copies passives) à l’aide d’E/S de 256 Ko. Les E/S sont séquentielles à 100 %. Dans Exchange 2010, le système est conçu afin que chaque base de données soit entièrement analysée une fois tous les sept jours.
Si l’analyse excède 7 jours, un événement est enregistré dans le journal des applications :
ID de l’événement : 733
Type d’événement : information
Source de l’événement : moteur ESE
Description : banque d’informations (15964) La tâche en arrière-plan de contrôle de parité de la base de données de maintenance en ligne MDB01 ne s’est PAS terminée à temps pour la base de données « d:\mdb\mdb01.edb ». Ce passage a démarré le 11/10/2011 et s’est exécuté pendant 604800 secondes (en 7 jours).
Si l’analyse de la copie de base de données active nécessite plus de sept jours, l’entrée suivante sera enregistrée dans le journal des applications, une fois l’analyse terminée:
ID de l’événement: 735
Type d’événement : information
Source de l’événement : moteur ESE
Description : banque d’informations (15964) La maintenance de la base de données MDB01 a effectué un passage complet sur la base de données « d:\mdb\mdb01.edb ». Ce passage a commencé le 11/10/2011 et s’est exécuté pendant un total de 777600 secondes. Cette tâche de maintenance de base de données a dépassé le seuil de réalisation de maintenance défini sur 7 jours. Effectuez l’une (ou plusieurs) des actions suivantes : augmentez les performances/le débit des E/S du volume hébergeant la base de données, réduisez la taille de la base de données et/ou réduisez les E/S de maintenance ne concernant par la base de données.
De plus, un avertissement sera aussi enregistré à la volée dans le journal des applications lorsque le passage nécessite plus de 7 jours.
Dans Exchange 2010, il existe maintenant deux modes pour exécuter le contrôle de parité de base de données sur les copies des bases de données actives :
- Exécuter en arrière plan 24 h sur 24 et 7 jours sur 7 Ce comportement par défaut doit être utilisé pour toutes les bases de données, particulièrement pour celles supérieures à 1 To. Exchange analyse la base de données une fois par jour. Ces E/S en lecture sont 100 % séquentielles et équivalent à un taux d’analyse d’environ 5 Mo/s sur la plupart des systèmes. Le processus d’analyse est monothread et limité par la latence des E/S. Plus la latence est élevée, plus le contrôle de parité de base de données est lent, car il attend plus longtemps que le dernier lot soit exécuté avant d’initier une autre analyse des pages (8 pages lues à la fois).
- Exécuter dans le processus de maintenance planifié de la base de données de boîtes aux lettres Quand vous activez cette option, le contrôle de parité de la base de données constitue la dernière tâche. Vous pouvez configurer sa durée d’exécution en modifiant la planification de la maintenance de la base de données de boîtes aux lettres. Cette option ne doit être utilisée qu’avec les bases de données dont la taille est inférieure à 1 To, ce qui requiert moins de temps pour exécuter une analyse complète.
Indépendamment de la taille de la base de données, il est recommandé de conserver le comportement par défaut et de ne pas configurer les opérations de contrôle de parité de base de données sur la base de données active comme processus planifié (à savoir, ne pas le configurer comme processus au sein de la période de maintenance en ligne).
Pour les copies de bases de données passives, les contrôles de parité interviennent pendant l’exécution et opèrent en permanence à l’arrière-plan.
Mise à jour corrective des pages
La mise à jour corrective des pages est le processus où les pages endommagées sont remplacées par des copies saines. Comme mentionné précédemment, la détection des pages endommagées est une fonction du contrôle de parité de base de données (de plus, les pages corrompues sont aussi détectées à l’exécution quand la page est stockée dans le cache de la base de données). La mise à jour corrective des pages fonctionne sur les copies de bases de données à haute disponibilité. Le mode de correction d’une page endommagée varie selon que la base de données à haute disponibilité est active ou passive.
Processus de mise à jour corrective des pages
| Sur les copies de bases de données actives | Sur les copies de bases de données passives |
|
|
Mise à zéro des pages
La mise à zéro des pages de données désigne le processus où les pages supprimées de la base de données sont écrites avec un modèle (mis à zéro) comme mesure de sécurité, ce qui rend la découverte des données beaucoup plus difficile.
Avec Exchange 2007 RTM et toutes les versions précédentes, les opérations de mise à zéro des pages intervenaient lors du processus de sauvegarde en flux continus. Et, de ce fait, elles n’étaient pas consignées dans le journal (à savoir, la mise à zéro des pages ne se traduisait pas par la génération de fichiers journaux). Cela posait un problème pour les bases de données répliquées, car les copies passive n’avaient jamais leurs pages mises à zéro et les copies actives ne les avaient mises à zéro que si vous effectuiez une sauvegarde en flux continus. Aussi, dans Exchange 2007 SP1, avons-nous introduit une nouvelle tâche facultative de maintenance en ligne, la mise à zéro des pages de bases de données pendant le contrôle de parité (pour plus d’informations, consultez Modifications du moteur ESE dans Exchange 2007 SP1 – Partie 2 (éventuellement en anglais)). Quand elle est activée, cette tâche met les pages à zéro pendant la période de maintenance en ligne, enregistrant les modifications, qui seront répliquées sur les copies passives.
Avec l’implémentation d’Exchange 2007 SP1, il existe un retard significatif entre le moment où une page est supprimée et celui où elle est mise à zéro comme résultat du processus de mise à zéro intervenant pendant une période de maintenance planifiée. Ainsi, dans Exchange 2010 SP1, la tâche de mise à zéro des pages est désormais un événement d’exécution qui opère en permanence, la mise à zéro des pages ayant lieu généralement lors de la transaction quand une suppression matérielle se produit.
En outre, les pages de base de données peuvent aussi être modifiées pendant le processus de contrôle de parité en ligne. Dans ce cas, les pages ciblées sont les suivantes :
- Les enregistrements supprimés qui n’ont pas été effacés à l’exécution en raison de tâches abandonnées (système surchargé) ou parce que la banque est l’objet d’une panne avant que les tâches ne modifient les données ;
- Tables supprimées et index secondaires. Quant ceux-ci sont supprimés, nous ne modifions pas activement leur contenu ; de ce fait, le contrôle de parité en ligne détecte si ces pages n’appartiennent plus à un objet valide et les modifie.
Pour plus d’informations sur la mise à zéro des pages dans Exchange 2010, consultez Présentation de la mise à zéro des pages Exchange 2010 (éventuellement en anglais).
Pourquoi ces tâches ne sont-elles pas exécutées simplement pendant une période de maintenance planifiée ?
La nécessité d’une période de maintenance planifiée pour la mise à zéro des pages, la défragmentation des bases de données, le compactage des bases de données et les opérations de contrôle de parité en ligne, pose des problèmes conséquents dont les suivants :
- Le fait d’avoir des opérations de maintenance planifiées rend très difficile la gestion 24 heures sur 24 et 7 jours sur 7 des centres de données qui hébergent les boîtes aux lettres de différents fuseaux horaires et ont peu ou pas de temps pour une période de maintenance planifiée. Le compactage des bases de données des versions Exchange antérieures n’avait aucun mécanisme de limitation et, comme les E/S sont essentiellement aléatoires, il pouvait conduire à une expérience utilisateur médiocre.
- Les bases de données de boîtes aux lettres Exchange 2010 déployées sur le stockage de niveau inférieur (par exemple, 7.2K SATA/SAS) ont une bande passante d’E/S réduite accessible au moteur ESE pour exécuter les tâches de période de maintenance. Il s’agit d’un problème, parce que cela signifie que les retards des E/S augmenteront pendant la période de maintenance, empêchant ainsi les activités de maintenance de s’achever au sein d’une période de temps désirée.
- L’utilisation de JBOD fournit un défi supplémentaire à la base de données en termes de vérification des données. Avec le stockage RAID, il est courant qu’un contrôleur de groupe analyse en arrière-plan un groupe de disques donné, en recherchant et en réaffectant les blocs défectueux. Un bloc (ou secteur) défectueux est un bloc d’un disque qui ne peut pas être utilisé en raison d’une détérioration permanente (par exemple, dégâts physiques subis par les particules du disque). Il est aussi courant qu’un contrôleur de groupe lise l’autre disque en miroir si un bloc défectueux a été détecté sur la demande de lecture initiale. Le contrôleur de groupe marque alors le bloc défectueux comme « défectueux » et écrit les données sur un nouveau bloc. Ces actions se produisent à l’insu de l’application, peut-être avec juste une légère augmentation de la latence de lecture du disque. Sans stockage RAID ou contrôleur de groupe, ces deux méthodes de détection et de correction des blocs défectueux ne sont plus disponibles. Sans stockage RAID, il appartient à l’application (ESE) de détecter les blocs défectueux et de les corriger (à savoir, contrôle de parité de la base de données).
- Les bases de données plus grandes des disques plus volumineux requièrent des périodes de maintenance plus longues pour maintenir l’aspect séquentiel/compact d’une base de données.
En raison des problèmes précédemment mentionnées, il était essentiel dans Exchange 2010 que les tâches de maintenance de base de données soient sorties d’un processus planifié et effectuées à l’arrière-plan de façon continue pendant l’exécution.
Ces tâches en arrière-plan n’impacteront-elles pas mes utilisateurs finaux ?
Nous avons conçu ces tâches en arrière-plan de telle sorte qu’elles soient automatiquement limitées en fonction de l’activité sur la base de données. En outre, nos instructions de dimensionnement des profils de message prennent ces tâches de maintenance en compte. Cependant, vous devez être attentif lorsque vous concevez votre architecture de stockage. Si vous prévoyez de stocker plusieurs bases de données sur le même LUN ou volume, assurez-vous que la taille totale de toutes les bases de données ne dépasse pas 2 To. La raison en est que la maintenance de base de données est limitée par la sérialisation en fonction du nombre de bases de données/volume et qu’elle présume que la taille totale n’excède pas 2 To.
Comment surveiller l’efficacité de ces tâches de maintenance en arrière-plan ?
Dans les versions précédentes d’Exchange, les événements du journal des applications étaient utilisés pour surveiller des opérations telles que la défragmentation en ligne. Dans Exchange 2010, il n’y a plus d’événements enregistrés pour les tâches de maintenance de défragmentation et de compactage. Cependant, vous pouvez utiliser les compteurs de performance pour suivre les tâches de maintenance en arrière-plan sous l’objet MSExchange Database ==> Instances :
| Compteur | Description |
| Durée de maintenance de la base de données | Nombre d’heures écoulées depuis la dernière maintenance complète de la base de données |
| Maintenance de base de données et contrôles de parité des pages défectueuses | Nombre de contrôles de parité de pages défectueuses pendant un passage de maintenance de base de données |
| Tâches de défragmentation | Nombre de tâches de défragmentation de base de données en arrière-plan en cours d’exécution |
| Tâches de défragmentation effectuées/s | Taux de tâches de défragmentation de base de données en arrière-plan en cours d’exécution |
Les compteurs suivants de mise à zéro des pages se trouvent sous l’objet MSExchange Database :
| Compteur | Description |
| Maintenance de base de données et pages mises à zéro | Indique le nombre de pages mises à zéro par le moteur de base de données depuis le dernier appel du compteur de performances |
| Maintenance de base de données et pages mises à zéro/s | Fréquence à laquelle les pages sont mises à zéro par le moteur de base de données |
Comment vérifier l’espace d’une base de données ?
Vous pouvez utiliser le Shell pour vérifier l’espace d’une base de données. Pour les bases de données de boîtes aux lettres, utilisez :
Get-MailboxDatabase MDB1 -Status | FL AvailableNewMailboxSpace
Pour les bases de données de dossiers publics, utilisez :
Get-PublicFolderDatabase PFDB1 –Status | FL AvailableNewMailboxSpace
Comment récupérer l’espace ?
Naturellement, une fois connu l’espace de la base de données, la question qui en découle est toujours la suivante : comment récupérer l’espace ?
Pour beaucoup, la réponse est d’effectuer une défragmentation hors connexion de la base de données avec ESEUTIL. Cependant, telle n’est pas notre recommandation. Quand vous effectuez une défragmentation hors connexion, vous créez une base de données entièrement nouvelle et les opérations effectuées pour créer cette base de données ne sont pas enregistrées dans les journaux de transaction. La nouvelle base de données possède une nouvelle signature, ce qui signifie que vous invalidez les copies de base de données associées à cette base de données.
Dans l’hypothèse où vous rencontrez une base de données qui possède un espace important et que vous ne vous attendez pas à ce que les opérations normales le revendiquent, notre recommandation est :
- Créer une base de données et les copies associées.
- Déplacer toutes les boîtes aux lettres vers la nouvelle base de données.
- Supprimer la base de données d’origine et ses copies associées.
Confusion terminologique
Une grande part de la confusion réside dans le terme maintenance de base de données en arrière-plan. Conjointement, toutes les tâches mentionnées plus haut composent la maintenance de base de données en arrière-plan. Cependant, le Shell, console de gestion Exchange et JetStress font tous deux référence au contrôle de parité de la base de données comme maintenance de base de données en arrière-plan, et c’est ce que vous configurez quand vous l’activez ou pas à l’aide de ces outils.
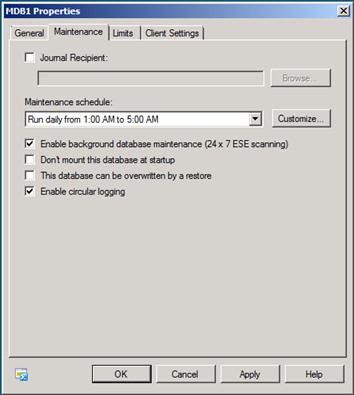
Figure 1 : Activation de la maintenance de base de données en arrière-plan pour une base de données utilisant la console de gestion Exchange">
Activation de la maintenance de base de données en arrière-plan avec le Shell :
Set-MailboxDatabase -Identity MDB1 -BackgroundDatabaseMaintenance $true
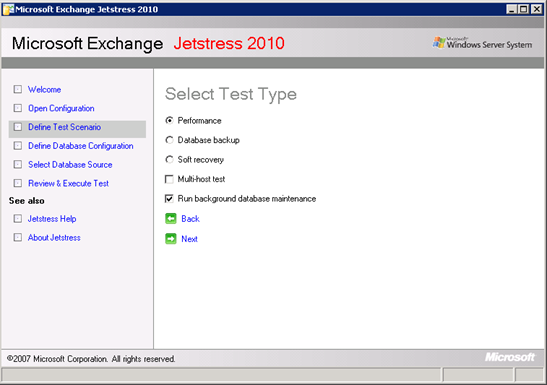
Figure 2 : Exécution de la maintenance de base de données en arrière-plan comme partie d’un test JetStress
Mon fournisseur de stockage a recommandé que je désactive le contrôle de parité de base de données comme tâche de maintenance de base de données en arrière-plan. Que dois-je faire ?
Le contrôle de parité de base de données peut devenir une réelle charge d’E/S si le stockage n’est pas conçu correctement (même s’il est séquentiel), car il effectue des E/S en lecture de 256 K et génère environ 5 Mo/s par base de données.
Dans le cadre de nos instructions de stockage , nous vous recommandons de configurer la taille de bande du groupe de stockage (taille des bandes écrites sur chaque disque d’un groupe ; aussi appelée taille de bloc) comme égale ou supérieure à 256 Ko.
Il importe aussi de tester votre stockage avec JetStress et de s’assurer que l’opération de contrôle de parité de base de données est incluse dans le passage du test.
À la fin, si une exécution JetStress échoue suite au contrôle de parité de base de données, vous avez quelques options :
Ne pas utiliser les agrégations par bande Utiliser les paires RAID-1 ou JBOD (ce qui peut nécessiter des modifications architecturales) et tirer le meilleur parti des modèles d’E/S séquentielles disponibles dans Exchange 2010.
Planifier Configurer le contrôle de parité de base de données pour qu’il ne soit pas un processus d’arrière-plan, mais un processus planifié. Quand nous avons implémenté le contrôle de parité de base de données comme processus d’arrière-plan, nous pensions que certains groupes de stockage seraient à tel point optimisés pour les E/S aléatoires (ou avec limitations de bande passante) qu’ils ne traiteraient pas correctement les E/S séquentielles de lecture. Telle est la raison pour laquelle nous l’avons conçu de telle sorte qu’il puisse être désactivé (ce qui déplace l’opération du contrôle de parité vers la période de maintenance).
Si vous procédez ainsi, nous vous recommandons des bases de données de plus petite taille. Gardez aussi à l’esprit que les copies passives effectuent toujours le contrôle de parité de base de données comme processus d’arrière-plan, et que de ce fait vous devrez toujours en tenir compte dans l’architecture du stockage. Pour plus d’informations sur le sujet, consultez JetStress 2010 et maintenance de base de données en arrière-plan (éventuellement en anglais).
Utiliser un autre stockage ou améliorer les capacités de stockage Choisir le stockage capable de répondre aux meilleures pratiques Exchange (bande 256 Ko+).
Conclusion
Les modifications architecturales du moteur de base de données dans Exchange Server 2010 améliorent de façon spectaculaire ses performances et sa robustesse, mais changent le comportement des tâches de maintenance de base de données par rapport aux versions précédentes. Nous espérons que cet article vous aura aidé à comprendre ce qu’est une maintenance de base de données en arrière-plan dans Exchange 2010.
Ross Smith IV
Responsable de programme principal
Expérience Client Exchange
Ce billet de blog a été traduit de l’anglais. L’article d’origine est disponible à la page Database Maintenance in Exchange 2010