Exchange 2010 中的数据库维护
原文发布于 2011 年 12 月 14 日(星期三)
在过去几个月,后台数据库维护一直是一个热门讨论话题:什么是后台数据库维护,为什么它对 Exchange 2010 数据库非常重要。希望您可以在本文中找到这些问题的答案。
需要对数据库执行哪些维护任务?
需要对 Exchange 数据库定期执行以下任务:
数据库压缩
数据库压缩的主要目的是释放数据库文件中未使用的空间(然而,要注意的是这不会将未使用的空间恢复到文件系统中)。目的是通过尽可能地将记录压缩到最少的页面中来释放数据库中的页面,从而减少所需的 I/O 量。通过获取数据库元数据(即数据库中描述数据库中表的信息)、访问每个表中的各个页面以及尝试将记录移动到按逻辑顺序排序的页面中,ESE 数据库引擎可实现此目的。
尽可能减少数据库文件占用的空间非常重要,原因如下:
- 减少备份数据库文件所需的时间
- 维护可预测的数据库文件大小,这对确定服务器/存储大小非常重要。
在 Exchange 2010 之前,数据库压缩操作是在联机维护阶段执行的。该过程在遍历数据库和跨页面重新排序记录时会产生随机 IO。该过程在先前的版本中的确不错,它通过释放数据库页面并重新排列记录,从而使页面总是按随机顺序排列。而与存储架构体系结构相结合意味着提取一组数据的任何请求(与下载文件夹中的项一样)总是产生随机 IO。
在 Exchange 2010 中,我们对数据库压缩进行了重新设计,现在连续性优先于空间压缩。此外,数据库压缩已不在联机维护阶段执行,它现在是持续运行的后台进程。
数据库碎片整理
数据库碎片整理是 Exchange 2010 中的新增功能,也称为 OLD v2 和 B+ 树碎片整理。它的作用是对带顺序标记/提示的数据库表进行压缩和碎片整理(使其有序可循)。对于在一段时间内有效利用磁盘资源(使 IO 更有序,而不是随机)和保持带顺序标记的表的紧凑性来说,数据库碎片整理非常重要。
可以将数据库碎片整理进程视为一个监视程序,用于监视其他数据库页面操作,以确定是否需要执行某项操作。该程序监视所有表中的可用页面,如果表达到阈值(即,B+ 树页面总计数中有相当多的页面处于空闲状态),它会将这些可用页面放回到根位置。它还用于维护使用顺序空间提示设置的表(使用已知的顺序使用模式创建的表)内的连续性。如果数据库碎片整理进程发现对顺序表进行了扫描/预先读取,但记录未存储在该表内的顺序页面上,该进程会通过将所有受影响页面移动到 B+ 树中的新扩展区域来对表的这一部分进行碎片整理。通过性能计数器(在监视部分中介绍)您可以发现,一旦达到稳定状态,数据库碎片整理要执行的工作微乎其微。
数据库碎片整理是一个后台进程,它在操作执行时持续分析数据库,然后根据需要触发异步操作。在下面两种情形下,会限制执行数据库碎片整理:
- 存在大量待处理任务:此时将阻止数据库碎片整理在数据库发生大量更改时首次执行大量工作。
- 存在 100ms 的延迟限制:系统过载时,数据库碎片整理开始推迟碎片整理工作。推迟的工作会在下次数据库处于相同的操作模式时执行。没有相关机制来记住推迟了哪项碎片整理工作并在系统有更多资源时返回来执行该工作。
数据库校验和检查
数据库校验和检查(也称为联机数据库扫描)是对数据库进行大量读取并对每个页面进行校验和检查(检查物理页面是否有损坏)的过程。校验和检查的主要目的是检测物理损坏情况和未执行的刷新操作,但无法通过事务性操作(陈旧页面)检测这些情况。
在 Exchange 2007 RTM 和所有先前的版本中,校验和检查操作在备份过程中执行。这会给复制数据库带来问题,因为要执行校验和检查的唯一副本是正在备份的副本。如果备份的是被动副本,这意味着不会对主动副本进行校验和检查。因此,在 Exchange 2007 SP1 中,我们引入了一个新的可选联机维护任务“联机维护校验和检查”(有关详细信息,请参阅 Exchange 2007 SP1 的 ESE 变化 – 第 2 部分(该链接可能指向英文页面))。
在 Exchange 2010 中,数据库扫描对数据库进行校验和检查并执行 Exchange 2010 存储崩溃后操作。空间可能会因崩溃而泄漏,并且联机数据库扫描会查找并发现失去的空间。对于每个主动扫描的数据库(主动副本和被动副本),数据库校验和检查使用 256KB IO 每秒读取大约 5 MB。I/O 全部是顺序 I/O。我们在设计 Exchange 2010 中的系统时是希望,每隔 7 天对每个数据库执行一次完整扫描。
如果扫描花费的时间长于 7 天,则会在应用程序日志中记录一个事件:
事件 ID: 733
事件类型: 信息
事件源: ESE
描述: 信息存储 (15964) MDB01: 数据库“d:\mdb\mdb01.edb”的联机维护数据库校验和检查后台任务未按时完成。此任务开始于 2011 年 10 月 11 日,到目前为止运行了 604800 秒(在 7 天之内)。
如果需要 7 天以上的时间才能完成对主动数据库副本的扫描,则扫描完成后会在应用程序日志中记录以下条目:
事件 ID: 735
事件类型: 信息
事件源: ESE
描述: 信息存储 (15964) MDB01 数据库维护已完成对数据库“d:\mdb\mdb01.edb”的全面检查。此检查开始于 2011 年 10 月 11 日,总共运行 777600 秒。这次数据库维护任务超出了 7 天的完成维护阈值。应该采取以下一种或多种措施: 增加托管数据库的卷的 IO 性能/吞吐量、减小数据库大小和/或减小非数据库维护 IO。(Database Maintenance has completed a full pass on database 'd:\mdb\mdb01.edb'. This pass started on 11/10/2011 and ran for a total of 777600 seconds. This database maintenance task exceeded the 7 day maintenance completion threshold. One or more of the following actions should be taken: increase the IO performance/throughput of the volume hosting the database, reduce the database size, and/or reduce non-database maintenance IO.)
此外,如果需要 7 天以上的时间才能完成,还会在应用程序日志中记录一个已发送警告。
在 Exchange 2010 中,现在可通过两种模式对主动数据库副本运行数据库校验和检查:
- 始终在后台运行:这是默认行为。它适用于所有数据库,特别是大于 1TB 的数据库。Exchange 每天最多扫描数据库一次。这种读取 I/O 完全是顺序 I/O(易于在磁盘上执行),这意味着在大多数系统上的扫描速度大约为 5 MB/s。该扫描过程是单线程的并且受 IO 延迟的限制。延迟越高,数据库校验和检查的速度越慢,因为需要花费更长的时间来等待上一批处理操作完成,之后才能发出另一页面的批处理扫描操作(一次读取 8 个页面)。
- 在计划内邮箱数据库维护过程中运行:选择这种方式后,数据库校验和检查是最后一项任务。可以通过更改邮箱数据库维护计划来配置检查的运行时长。这种方式仅适用于小于 1 TB 的数据库,此类数据库需要较短的时间即可完成完整扫描。
无论数据库大小如何,均建议您采用默认行为,并且不要将针对主动数据库的数据库校验和检查操作配置为计划内过程(即不将它配置为联机维护阶段中的过程)。
对于被动数据库副本,数据库校验和检查在运行时执行,并且在后台持续运行。
页面修补
页面修补是由正常副本替换已损坏页面的过程。如前所述,检测已损坏页面是一项数据库校验和检查功能(此外,还会在页面存储到数据库缓存中时对已损坏页面进行运行时检测)。页面修补适用于高可用 (HA) 数据库副本。已损坏页面的修补方式取决于 HA 数据库副本是主动副本还是被动副本。
页面修补过程
| 对于主动数据库副本 | 对于被动数据库副本 |
|
|
页面清零
数据库页面清零过程使用一种清零模式作为安全措施来重写数据库中的已删除页面,该过程会使发现数据变得更加困难。
在 Exchange 2007 RTM 和所有先前的版本中,页面清零操作在流式备份过程中执行。此外,因为这些操作在流式备份过程中执行,所以系统不会记录此类操作(即页面清零不会生成日志文件)。这会给复制数据库带来问题,因为被动副本绝对不会将它的页面清零,而主动副本仅在您执行流式备份时才会将它的页面清零。因此,在 Exchange 2007 SP1 中,我们引入了一个新的可选联机维护任务“校验和检查期间的数据库页面清零”(有关详细信息,请参阅 Exchange 2007 SP1 的 ESE 变化 – 第 2 部分(该链接可能指向英文页面))。启用时,该任务会在联机维护阶段将页面清零并记录更改,这些更改将会复制到被动副本。
对于 Exchange 2007 SP1 实现,删除页面和页面清零(因在计划内维护阶段执行清零过程而发生)之间有很长时间的间隔。因此,在 Exchange 2010 SP1 中,页面清零任务现在是持续运行的运行时事件,即,页面清零通常在发生硬删除时在执行事务时执行。
此外,在联机校验和检查过程中也会擦除数据库页面。这里所说的页面是指:
- 运行时因删除任务(系统过载时)或者因任务成功擦除数据之前存储崩溃而未能擦除的已删除记录;
- 已删除的表和辅助索引。删除这些内容时,我们不会主动擦除它们的内容,因此联机校验和检查会确认这些页面不再属于任何有效对象并擦除它们。
有关 Exchange 2010 中页面清零的详细信息,请参阅了解 Exchange 2010 页面清零。
为什么不直接在计划内维护阶段执行这些任务?
如果在计划内维护阶段执行页面清零、数据库碎片整理、数据库压缩和联机校验和检查操作,则会带来严重问题,包括:
- 执行计划内维护操作会导致很难管理托管各时区邮箱的 24 小时不间断运行的数据中心,并导致计划内维护时间不足或完全没有时间进行此维护。Exchange 早期版本中的数据库压缩没有限制机制,并且 IO 主要是随机 IO,这可能会导致用户体验欠佳。
- 部署在较低层存储(例如 7.2K SATA/SAS)的 Exchange 2010 邮箱数据库在 ESE执行维护期任务时可用的有效 IO 带宽较低。这会带来问题,因为这意味着维护阶段的 IO 延迟会增加,从而妨碍在所需时间段内完成维护活动。
- 使用 JBOD 在数据验证方面带来了其他数据库问题。对于 RAID存储,阵列控制器通常在后台扫描给定磁盘组以查找和重新分配坏块。坏块(又称扇区)是指磁盘上因永久损坏(例如,磁盘粒子上发生的物理损坏)而无法使用的块。如果在发出初始读取请求时检测到坏块,阵列控制器通常还会读取备用镜像磁盘。阵列控制器接着会将坏块标记为“损坏”并将数据写入新块。所有这些行为出现时应用程序毫不知情,或许只是磁盘读取延迟略有增加。如果不使用 RAID 或阵列控制器,那么这两种坏块检测和修补方法都不再可行。如果没有 RAID,则由应用程序 (ESE) 检测和修补坏块(即进行数据库校验和检查)。
- 大型磁盘上的大型数据库需要更长的维护时间来维护数据库的有序性/紧凑性。
鉴于上述问题,在 Exchange 2010 中,数据库维护任务已不在计划内过程中执行,而是运行时在后台持续执行,这一点至关重要。
这些后台任务不会影响最终用户吗?
我们已对这些后台任务进行了设计,系统会根据数据库的活动自动限制这些任务。此外,我们的确定邮件配置文件大小的指南也考虑到了这些维护任务。然而,在设计存储体系结构时一定要谨慎。如果计划在同一 LUN 或卷上存储多个数据库,请确保所有数据库的总大小不超过 2 TB。这是因为在基于数据库/卷的数目进行序列化时,数据库维护将受到限制,并且假定总大小不超过 2 TB。
如何监视这些后台维护任务的有效性?
在 Exchange 先前的版本中,可使用应用程序日志中的事件监视联机碎片整理等活动。在 Exchange 2010 中,不再针对碎片整理和压缩维护任务记录任何事件。然而,可使用 MSExchange Database ==> Instances 对象下的性能计数器跟踪后台维护任务:
| 计数器 | 说明 |
| Database Maintenance Duration | 自上次维护该数据库后所经过的小时数 |
| Database Maintenance Pages Bad Checksums | 在数据库维护阶段出现的无法更正的页面校验和数目 |
| Defragmentation Tasks | 当前正在执行的后台数据库碎片整理任务数 |
| Defragmentation Tasks Completed/Sec | 要完成的后台数据库碎片整理任务的速度 |
MSExchange Database 对象下提供了以下页面清零计数器:
| 计数器 | 说明 |
| Database Maintenance Pages Zeroed | 指示自调用性能计数器后由数据库引擎清零的页面数 |
| Database Maintenance Pages Zeroed/sec | 指示数据库引擎对页面清零的速度 |
如何查看数据库中的空白区域?
可使用命令行管理程序查看数据库中的可用空白区域。对于邮箱数据库,请使用:
Get-MailboxDatabase MDB1 -Status | FL AvailableNewMailboxSpace
对于公用文件夹数据库,请使用:
Get-PublicFolderDatabase PFDB1 –Status | FL AvailableNewMailboxSpace
如何回收空白区域?
查看数据库中的可用空白区域后,人们往往会自然想到这个问题:如何回收空白区域?
很多人认为,答案是使用 ESEUTIL 对数据库执行脱机碎片整理。然而,我们建议不要这样做。如果执行脱机碎片整理,则会创建全新的数据库,并且为创建该新数据库而执行的操作不会记录在事务日志中。新数据库还具有新数据库签名,这意味着与该数据库关联的数据库副本会失效。
如果遇到数据库存在大量空白区域的情况,而且您认为一般操作无法回收它,则我们建议:
- 创建新数据库和关联的数据库副本。
- 将所有邮箱移动到新数据库。
- 删除原始数据库及其关联的数据库副本。
术语误解
大部分人会误解术语后台数据库维护。广义上讲,前面所述的全部任务合起来称为后台数据库维护。然而,命令行管理程序、EMC 和 JetStress 都将数据库校验和检查称为后台数据库维护,使用这些工具启用或禁用后台数据库维护时实际上配置的是数据库校验和检查。
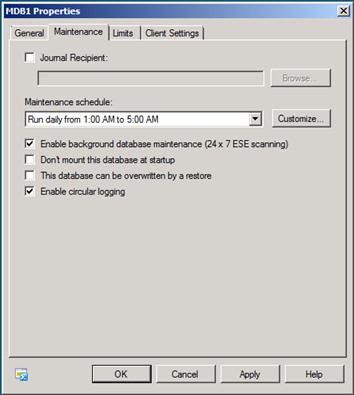
图 1:使用 EMC 对数据库启用后台数据库维护
使用命令行程序启用后台数据库维护:
Set-MailboxDatabase -Identity MDB1 -BackgroundDatabaseMaintenance $true
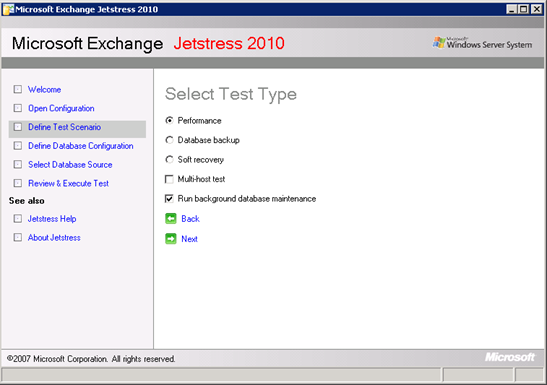
图 2:在 JetStress 测试期间运行后台数据库维护
存储供应商建议我不要将数据库校验和检查作为后台维护任务,我应该怎么办?
如果没有正确设计存储,数据库校验和检查可能会成为 IO 负担(尽管是顺序 IO),因为它执行 256K 读取 IO,对每个数据库的检查速度大约为 5MB/s。
在我们的存储指南中,建议您将存储阵列带区大小(写入阵列中每个磁盘的带区的大小;也称为块大小)配置为 256KB 或更大的值。
使用 JetStress 测试存储(该链接可能指向英文页面),并确保在测试期间执行数据库校验和检查操作也很重要。
最后,如果 JetStress 操作因数据库校验和检查失败,可以采用以下任意方法:
不要使用带区:使用 RAID-1 对或 JBOD(可能需要更改体系结构),并充分利用 Exchange 2010 中提供的顺序 IO 模式。
安排数据库校验和检查:配置数据库校验和检查,使它不再是后台进程,而是计划内过程。将数据库校验和检查作为后台进程实现时,我们了解到会针对随机 IO 优化某些存储阵列(或者这些阵列具有带宽限制),以至于它们无法很好地处理顺序读取 IO。这就是我们在构建时设计了禁用选项的原因(禁用时校验和检查操作会改在维护阶段执行)。
如果这样做,建议您使用较小的数据库大小。还要记住,被动副本仍将数据库校验和检查作为后台进程执行,因此,您仍需要在存储体系结构中考虑这部分吞吐量。有关该主题的详细信息,请参阅 Jetstress 2010 和后台数据库维护(该链接可能指向英文页面)。
使用其他存储或提高存储容量:选择能够满足 Exchange 最佳实践要求的存储(256KB+ 带区大小)。
结束语
Exchange Server 2010 中数据库引擎的体系结构变化显著提高了它的性能和稳定性,而且改变了先前版本中数据库维护任务的行为。希望本文可帮助您了解 Exchange 2010 中的后台数据库维护。
Ross Smith IV
首席项目经理
Exchange 客户体验团队
这是一篇本地化的博客文章。请访问 Database Maintenance in Exchange 2010 以查看原文