Manutenção do banco de dados no Exchange 2010
Artigo original publicado na quarta-feira, 14 de dezembro de 2011
Nos últimos meses, houve uma discussão significativa sobre o que é uma manutenção básica do banco de dados e por que ela é importante para os bancos do Exchange 2010. Espero que esse artigo aos responda a essas perguntas
Quais tarefas de manutenção precisam ser executadas no banco de dados?
As tarefas a seguir precisam ser executadas rotineiramente nos bancos de dados do Exchange:
- Compactação do banco de dados
- Desfragmentação do banco de dados
- Soma de verificação do banco de dados
- Correção de página
- Zeragem de página
Compactação do banco de dados
O objetivo primário da compactação do banco de dados é liberar espaço não usado dentro do arquivo do banco de dados (no entanto, deve ser observado que isso não retorna esse espaço ao sistema de arquivos). A intenção é liberar as páginas no banco de dados compactando os registros para o menor número de páginas possível, reduzindo assim o valor de I/O necessário. O mecanismo de banco de dados ESE faz isso pegando os metadados do banco de dados, que são as informações dentro do banco que descrevem as tabelas e, cada tabela, visitando cada página da tabela, e tentando mover registros para páginas logicamente ordenadas.
Manter um espaço magro do arquivo do banco de dados é importante por vários motivos, incluindo:
- Reduzir o tempo associado ao backup do arquivo do banco de dados
- Manter um tamanho previsível do arquivo do banco de dados, que é importante para fins de dimensionamento do servidor/armazenamento.
Prior Antes do Exchange 2010, as operações de compactação do banco de dados eram executadas durante a janela de manutenção online. Esse processo produzia um IO aleatório, porque ele percorria o banco de dados e reordenava os registros pelas páginas. Esse processo era literalmente bom demais nas versões anteriores – liberando as páginas do banco de dados e reordenando os registros, as páginas ficavam sempre em ordem aleatória. Combinado com a arquitetura do esquema do armazenamento, isso significava que qualquer solicitação para recuperar um conjunto de dados (como baixar itens dentro de uma pasta) sempre resultava em um IO aleatório.
No Exchange 2010, a compactação do banco de dados foi redesenhada, de forma que a contiguidade é preferível à compactação de espaço. Além disso, a compactação do banco de dados retirada da janela de manutenção online e agora é um processo de segundo plano que executa continuamente.
Desfragmentação do banco de dados
A desfragmentação do banco de dados é uma novidade no Exchange 2010 e também é chamada de OLD v2 e desfragmentação de árvore B+. Sua função é compactar e desfragmentar (tornar sequenciais) tabelas do banco de dados que foram marcadas como sequenciais. A desfragmentação é importante para manter a utilização eficiente dos recursos do disco com o passar do tempo (tornar o IO mais sequencial, e não aleatório) e manter a compactação das tabelas marcadas como sequenciais.
Você pode pensar no processo de desfragmentação do banco de dados como um monitor que supervisiona outras operações da página do banco de dados, para determinar se há trabalho para fazer. Ele monitora todas as tabelas para ver se há páginas livres, e se uma tabela chegar ao limite onde uma porcentagem alta significativa da contagem de páginas da Árvore B+ for livre, ele retorna as páginas livres à raiz. Ela também funciona para manter a continuidade dentro de uma tabela configurada com dicas de espaço sequencial (uma tabela criada com um padrão de uso sequencial conhecido). Se a desfragmentação do banco de dados vir uma digitalização/pré-leitura em uma tabela sequencial e os registros não estiverem armazenados nas páginas sequenciais dentro da tabela, o processo irá desfragmentar essa seção, movendo todas as páginas afetadas para uma nova extensão na árvore B+. Você pode usar os contadores do desempenho (mencionados na seção de monitoração) para ver como o processo de desfragmentação do banco de dados faz um trabalho pequeno depois que o estado estável é atingido.
A desfragmentação é um processo de segundo plano que analisa o banco de dados continuamente enquanto as operações são executadas e depois aciona o trabalho assíncrono quando necessário. Ela é acelerada em dois cenários:
- O número máximo de tarefas pendentes Isso impede que a desfragmentação do banco de dados faça um trabalho muito grande na primeira passagem, se uma alteração massiva ocorreu
- Uma aceleração de latência de 100ms Quando o sistema é sobrecarregado, a desfragmentação do banco de dados é iniciada. O trabalho iniciado é executado na próxima vez que o banco de dados passar pelo mesmo padrão operacional. Não há nada que lembre que o trabalho de desfragmentação foi iniciado e volte e o execute assim que o sistema tiver mais recursos.
Soma de verificação do banco de dados
O checksumming do banco de dados (também conhecido como Verificação Online do Banco de Dados) é o processo onde o banco de dados é lido em pedaços grandes e cada página é verificada (quanto à corrupção de página física). O objetivo primário da soma de verificação é detectar corrupção física e liberações perdidas que talvez não estejam sendo detectadas pelas operações de transação (páginas obsoletas).
Com o Exchange 2007 RTM e todas as versões prévias, as operações de soma de verificação ocorriam durante o processo de backup. Isso era um problema para os bancos de dados replicados, pois a única cópia a ser verificada era a do backup. Para o cenário em que a cópia passiva é submetida ao backup, isso significava que a ativa não estava sendo verificada. Portanto, no Exchange 2007 SP1, introduzimos uma nova tarefa opcional de manutenção online, a Soma de Verificação da Manutenção Online (consulte mais informações em Alterações no Exchange 2007 SP1 ESE – Parte 2).
No Exchange 2010, a varredura do banco de dados faz uma soma de verificação do banco e executa as operações após o travamento do Repositório do Exchange 2010. O espaço pode ser vazado devido ao tratamento e a varredura do banco de dados online encontra e recupera o espaço perdido. A soma de verificação do banco de dados lê aproximadamente 5 MB por segundo para cada banco de varredura ativa (cópias ativa e passiva) usando IOs de 256KB . O I/O é 100 por cento sequencial. O sistema no Exchange 2010 foi projetado com a expectativa de que cada banco de dados seja submetido a uma varredura completa a cada sete dias.
Se a varredura demorar mais de sete dias, um evento é registrado no Log do Aplicativo:
ID do evento: 733
Tipo de evento: Informação
Origem do evento: ESE
Descrição: Repositório de informações (15964) MDB01: Tarefa de segundo plano Soma de Verificação do Banco de Dados de Manutenção Online NÃO está finalizando no prazo para o banco de dados 'd:\mdb\mdb01.edb'. Essa passagem começou em 11/10/2011 e tem executado por 604800 segundos (mais de 7 dias) até o momento.
Se demorar mais de 7 dias para concluir a varredura da cópia ativa do banco de dados, a entrada a seguir será registrado no Log do Aplicativo uma vez que a varredura termine:
ID do evento: 735
Tipo de evento: Informação
Origem do evento: ESE
Descrição: Repositório de informações (15964) MDB01 Manutenção do Banco de Dados concluiu uma passagem completa no banco 'd:\mdb\mdb01.edb'. Essa passagem começou em 11/10/2011 e executou por um total de 777600 segundos. Essa tarefa de manutenção do banco de dados excedeu o limite de conclusão de manutenção de 7 dias. Uma ou mais das ações a seguir deve ser tomada: aumentar o desempenho/rendimento do IO do volume que hospeda o banco de dados, reduzir o tamanho do banco de dados e/ou reduzir o IO da manutenção que não seja do banco de dados.
Além disso, um aviso durante o processo também será registrado no Log do Aplicativo quando a tarefa demorar mais de 7 dias para terminar.
No Exchange 2010, agora há duas formas de executar a soma de verificação do banco de dados nas cópias ativas:
- Executar em segundo plano 24×7 Esse é o comportamento padrão. Ele deveria ser usado para todos os bancos de dados, principalmente os maiores que 1TB. O Exchange verifica o banco no máximo uma vez por dia. Esse I/O de leitura é 100 por cento sequencial (o que facilita no disco) e equivale a uma taxa de varredura de cerca de 5 megabytes (MB)/s na maioria dos sistemas. O processo de varredura tem um único segmento e é acelerado pela latência do IO. Quanto mais alta a latência, mais lenta a soma de verificação do banco de dados, porque ela espera mais pela conclusão do último lote antes de emitir outra varredura em um lote de páginas (8 páginas são lidas de cada vez).
- Executar no processo de manutenção do banco de dados da caixa postal programado Quando você seleciona essa opção, a soma de verificação do banco de dados é a última tarefa. Você pode configurar por quanto tempo ela executa alterando a programação da manutenção do banco de dados de caixa postal. Essa opção só deve ser usada com bancos de dados com menos de 1 terabyte (TB) de tamanho, que exigem menos tempo para concluir uma varredura completa.
Independente do tamanho do banco de dados, nossa recomendação é utilizar o comportamento padrão e não configurar as operações de soma de verificação contra o banco de dados ativo como um processo programado (isto é, não configurar como um processo dentro da janela da manutenção online).
Para cópias passivas do banco de dados, as somas de verificação ocorrem durante o tempo de execução, operando continuamente em segundo plano.
Correção de página
A correção de página é o processo em que páginas corrompidas são substituídas por cópias saudáveis. Como mencionado, a detecção de uma página corrompida é uma função da soma de verificação do banco de dados (além disso, as páginas corrompidas também são detectadas no tempo de execução, quando armazenadas no cache do banco de dados). A correção de páginas funciona contra cópias do banco de dados altamente disponíveis (HA). A forma como uma página corrompida é corrigida depende de a cópia do banco de dados HA ser ativa ou passiva.
Processo de correção de página
| Em cópias ativas do banco de dados | Em cópias passivas do banco de dados |
|
|
Zeragem de página
Zeragem de página do banco de dados é o processo em que as páginas escolhidas do banco de dados são substituídas por um padrão (zerado) como medida de segurança, o que torna a descoberta dos dados muito mais difícil.
No Exchange 2007 RTM e todas as versões prévias, as operações de zeragem de página ocorriam durante o processo de backup do streaming. Além disso, uma vez que ocorria durante esse processo, esta não era uma operação registrada (por exemplo, a zeragem de página não resultava na geração de arquivos de log). Isso era um problema para os bancos de dados replicados, porque as cópias passivas nunca tinham suas páginas zeradas, e as páginas das cópias ativas só eram zeradas se você realizasse um backup de streaming. Portanto, no Exchange 2007 SP1, apresentamos uma nova tarefa de manutenção online opcional, Zerar Páginas do Banco de Dados durante a Soma de Verificação (para obter mais informações, consulte Alterações no Exchange 2007 SP1 ESE – Parte 2). Quando ativada, essa tarefa zera as páginas durante a janela da manutenção online e registra as operações que seriam replicadas para as cópias passivas.
Com a implementação do Exchange 2007 SP1, há atraso significativo entre quando uma página é excluída e quando é zerada como resultado do processo ocorrido durante uma janela de manutenção programada. Assim, no Exchange 2010 SP1, a tarefa de zeragem da página é agora um evento de tempo de execução que opera continuamente, zerando as páginas normalmente no momento da transação quando uma eliminação definitiva ocorre.
Além disso, as páginas do banco de dados também podem ser lidas durante o processo de soma de verificação online. As páginas-alvo neste caso são:
- Registros excluídos que não puderam ser limpos durante o tempo de execução, devido às tarefas descartadas (se o sistema estiver muito sobrecarregado) ou porque o Repositório travou antes que as tarefas pudessem limpar os dados;
- Tabelas e índices secundários excluídos. Quando esses são excluídos, nós não limpamos seu conteúdo ativamente, portanto a soma de verificação online detecta que essas páginas não pertencem mais a qualquer objeto válido e as limpa.
Para obter mais informações sobre a zeragem de página no Exchange 2010, consulte Entendendo a zeragem de página no Exchange 2010.
Por que essas tarefas não são simplesmente executadas durante uma janela de manutenção programada?
Exigir uma janela de manutenção programada para a zeragem de página, a desfragmentação e a compactação do banco de dados e as operações de soma de verificação online impõe problemas significativos, incluindo o seguinte:
- A presença de operações de manutenção programadas dificulta o gerenciamento de datacenters 24x7 que hospedam caixas postais de vários fusos horários e possuem pouco ou nenhum tempo para uma janela de manutenção programada. Nas versões prévias do Exchange, a compactação do banco de dados não tinha mecanismos de aceleração e uma vez que o IO é predominante aleatório, ele pode causar uma experiência ruim para o usuário.
- Os bancos de dados de caixa postal do Exchange 2010 implantados em armazenamento de camada inferior (por exemplo, 7.2K SATA/SAS) têm uma largura de banda de IO efetiva reduzida disponível para que o ESE execute tarefas da janela de manutenção. Isso é um problema porque significa que as latências do IO aumentarão durante a janela de manutenção, impedindo assim que as atividades de manutenção terminem dentro de um período desejado.
- O uso de JBOD fornece um desafio adicional para o banco de dados em termos de verificação de dados. Com o armazenamento RAID, é comum que um controlador de matriz faça uma varredura em segundo plano de um determinado grupo de discos, localizando e reatribuindo os blocos ruins. Um bloco ruim (também conhecido como setor) é um bloco no disco que não pode ser usado devido a um dano permanente (por exemplo, dano físico infligido nas partículas do disco). Também é comum que um controlador de matriz leia o disco espelhado alternativo se um bloco ruim for detectado na solicitação de leitura inicial. Subsequentemente, o controlador de matriz irá marcar o bloco como "ruim" e gravar os dados em um novo bloco. Tudo isso ocorre sem que o aplicativo saiba, talvez com um leve aumento na latência de leitura do disco. Sem o RAID ou um controlador de matriz, a detecção desses blocos ruins e os métodos de solução não estão mais disponíveis. Sem o RAID, cabe ao aplicativo (ESE) detectar os blocos ruins e solucionar (isto é, soma de verificação do banco de dados).
- Bancos de dados maiores em discos maiores exigem períodos de manutenção mais longos, para manter a sequência/compactação do banco de dados.
Devido aos problemas mencionados, no Exchange 2010 era crítico que as tarefas de manutenção do banco de dados fossem movidas de um processo programado e executadas continuamente em segundo plano durante o tempo de execução.
Essas tarefas de segundo plano não irão afetar meus usuários finais?
Projetamos essas tarefas de segundo plano para que não sejam aceleradas automaticamente com base na atividade que ocorre contra o banco de dados. Além disso, nossa orientação de tamanhos quanto ao perfis de mensagem levam essas tarefas de manutenção em consideração. No entanto, você deve tomar cuidado ao projetar sua arquitetura de armazenamento. Se você planeja armazenar diversos bancos de dados no mesmo LUN ou volume, certifique-se de que o tamanho agregado de todos os bancos não exceda 2 TB. Isso ocorre porque a manutenção do banco de dados é acelerada pela serialização, com base nos bancos de dados/volumes, e presume que o tamanho agregado não seja maior que 2 TB.
Como posso monitorar a efetividade dessas tarefas de manutenção de segundo plano?
Nas versões prévias do Exchange, eventos no Log do Aplicativo seriam usados para monitorar coisas como a desfragmentação online. No Exchange 2010, os eventos não são mais registrados para as tarefas de manutenção de desfragmentação e compactação. No entanto, você pode usar os contadores de desempenho para rastrear as tarefas de manutenção de segundo plano sob o objeto MSExchange Database ==> Instances:
| Contador | Descrição |
| Duração da manutenção do banco de dados | O número de horas que se passaram desde o término da última manutenção para esse banco de dados |
| Somas de verificação de páginas ruins da manutenção do banco de dados | O número de somas de verificação de páginas incorrigíveis encontradas durante uma passagem de manutenção do banco de dados |
| Tarefas de desfragmentação | A contagem das tarefas de desfragmentação do banco de dados em segundo plano que estão em execução atualmente |
| Tarefas de desfragmentação concluídas/s | A taxa de tarefas de desfragmentação do banco de dados em segundo plano que estão sendo concluídas |
Você encontrará os seguintes contadores de zeragem da página no objeto MSExchange Database:
| Contador | Descrição |
| Páginas de manutenção do banco de dados zeradas | Indica o número de páginas zeradas pelo mecanismo do banco de dados desde que o contador de desempenho foi invocado |
| Páginas de manutenção do banco de dados zeradas/s | Indica a taxa em que as páginas são zeradas pelo mecanismo do banco de dados |
Como posso verificar o espaço em branco em um banco de dados?
Você pode usar o Shell para verificar o espaço em branco disponível em um banco de dados. Para bancos de dados de caixa postal, use:
Get-MailboxDatabase MDB1 -Status | FL AvailableNewMailboxSpace
Para bancos de dados de pasta pública, use:
Get-PublicFolderDatabase PFDB1 –Status | FL AvailableNewMailboxSpace
Como eu posso reformar o espaço em branco?
Naturalmente, depois de ver o espaço em branco disponível no banco de dados, a pergunta que sempre resulta é - como eu posso reformar o espaço em branco?
Muitos presumem que a resposta é executar uma desfragmentação offline do banco de dados usando o ESEUTIL. No entanto, essa não é nossa recomendação. Quando você executa uma desfragmentação offline, cria um banco de dados completamente novo e as operações executadas para criá-lo não estão conectadas a log de transação. O novo banco também tem uma nova assinatura, o que significa que você invalida as cópias associadas a esse banco de dados.
Caso você encontre um banco de dados que tenha um espaço em branco significativo, e não é previsto que as operações normais o reformem, nossa recomendação é:
- Criar um novo banco de dados e as cópias associadas.
- Mover todas as caixas postais para o novo banco de dados.
- Excluir o banco de dados original e suas cópias associadas.
Uma confusão de terminologia
Grande parte da confusão está no termo manutenção do banco de dados em segundo plano. Coletivamente, todas as tarefas mencionadas compõem a manutenção do banco de dados em segundo plano. No entanto, o Shell, o EMC e o JetStress se referem à soma de verificação do banco de dados como manutenção do banco de dados em segundo plano, e isso é o que você configura ao ativar ou desativar usando essas ferramentas.
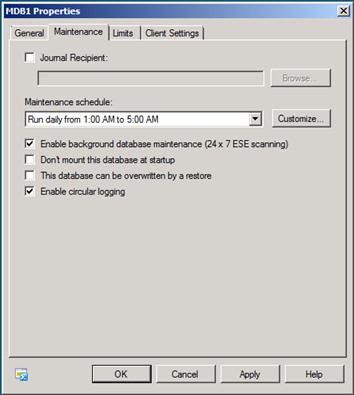
Figura 1: Ativando a manutenção em segundo plano para um banco de dados usando o EMC
Ativando a manutenção em segundo plano para um banco de dados usando o Shell:
Set-MailboxDatabase -Identity MDB1 -BackgroundDatabaseMaintenance $true
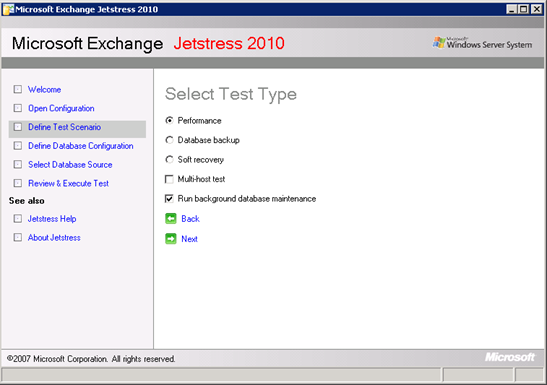
Figura 2: Executando a manutenção do banco de dados em segundo plano como parte de um teste do JetStress
Meu fornecedor de armazenamento recomendou que eu desabilite o soma de verificação do banco de dados como uma tarefa de manutenção em segundo plano, o que devo fazer?
A soma de verificação do banco de dados pode se tornar um fardo do IO se o armazenamento não for projetado corretamente (embora seja sequencial), porque execute IOS de leitura de 256K e gera cerca de 5MB/s por banco de dados.
Como parte da nossa orientação de armazenamento, recomendamos configurar o tamanho da faixa da sua matriz (o tamanho das faixas gravadas em cada disco na matriz; também denominada tamanho do bloco) como 256KB ou mais.
Também é importante testar seu armazenamento com o JetStress e garantir que a operação de soma de verificação no banco de dados seja incluída na passagem do test
No final, se uma execução do JetStress falhar devido à soma de verificação do banco de dados, você tem algumas opções:
Não use as faixas Use pares RAID-1 ou JBOD (que pode exigir alterações arquitetônicas) e obtenha o máximo de benefícios dos padrões de IO sequenciais disponíveis no Exchange 2010.
Programe Configure a soma de verificação do banco de dados para não ser um processo de segundo plano, mas um processo programado. Quando a soma é implementada como um processo de segundo plano, entendemos que algumas matrizes de armazenamento seriam tão otimizadas para o IO aleatório (ou teriam limitações de largura de banda) que não poderiam lidar bem com o IO da leitura sequencial. É por isso que a criamos para que possa ser desativada (movendo assim a operação de soma de verificação para a janela de manutenção).
Se você fizer isso, recomendamos tamanhos do banco de dados menores. Lembre também que as cópias passivas ainda executarão a soma de verificação do banco de dados como um processo de segundo plano, portanto você ainda precisa considerar esse fato para o rendimento na nossa arquitetura de armazenamento. Para obter mais informação sobre esse assunto, consulte Jetstress 2010 e manutenção do banco de dados em segundo plano.
Use um armazenamento diferente ou aprimore suas capacidades Escolha um armazenamento capaz de atender às práticas recomendadas do Exchange (tamanho de faixa 256KB+).
Conclusão
As alterações arquitetônicas no mecanismo do banco de dados no Exchange Server 2010 aprimoram drasticamente o desempenho e a robustez, mas mudam o comportamento das tarefas de manutenção do banco de dados de versões prévias. Espero que esse artigo o ajude a entender o que é a manutenção do banco de dados em segundo plano no Exchange 2010.
Ross Smith IV
Gerente de programa principal
Experiência do cliente do Exchange
Este é um post de um blog localizado. Encontre o artigo original em Database Maintenance in Exchange 2010