如何写出高效能TSQL -深入浅出SQL Server Relational Engine (含 SQL 2014 in-memory Engine)
原文地址:https://blogs.technet.com/b/technet_taiwan/archive/2015/01/16/tsql-series-0116.aspx
简介
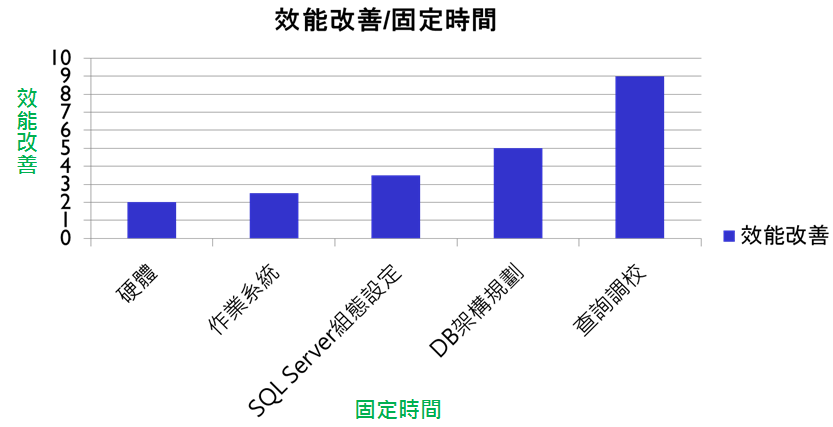
良好的TSQL和正确索引是大幅提高查询效能最快的快捷方式,同时TSQL也是使用SQL Server的核心,任何应用程序想要和SQL Server沟通,都无法避免撰写TSQL,所以各种效能调校方法中,我们认为查询调校是最省成本、最快能感受到效果的方法 (如下图),这一系列文章将为大家介绍如何写出高效能TSQL,以及开发人员必须了解SQL Server相关基本知识和观念,这样才能活用相关技术,并发挥SQL Server无限潜能。
SQL Server 关系型引擎
SQL Server数据库引擎主要有两部分,这我们里不讨论储存引擎(storage engine)架构,而将会着重在关系型引擎。
由于SQL Server处理查德询过程步骤相当繁琐,当一句TSQL送给SQL Server时,我们须了解关系型引擎是如何工作的,因为每一句TSQL都必须透过关系型引擎分析处理,最后才会透过储存引擎执行并返回用户所需的数据结果集,理解关系型引擎不仅可以帮我们预先避开效能陷阱,同时也有助于我们减少查询调校和除错时间,下面我将说明几个处理关键步骤。
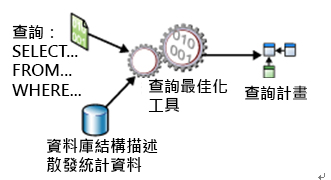
图一:SQL Server处理查询简单示意
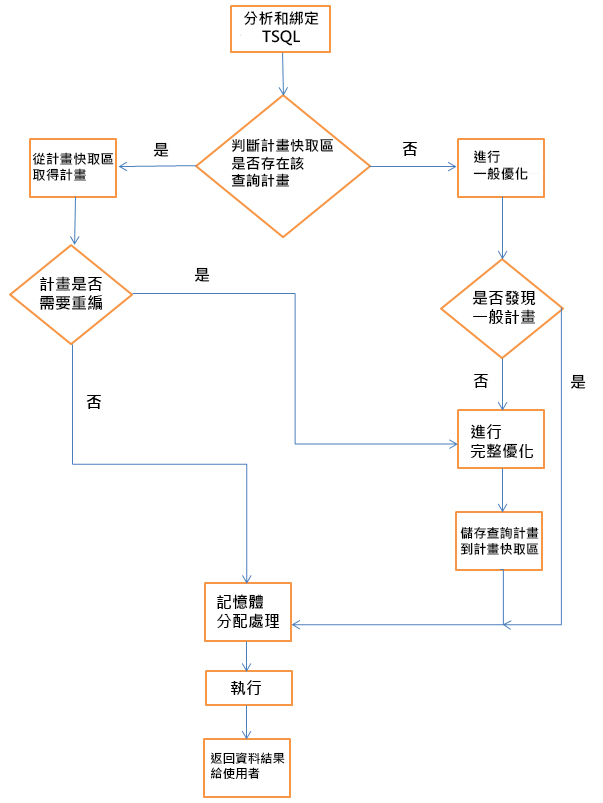
图二:SQL Server处理查询关键步骤流程图
分析和绑定
一开始查询优化器会先确认语法正确性,如有错误将会立即返回错误讯息给用户,如果没有错误就会建立分析树并进行对象绑定 (如数据表字段是否存在、数据型别是否正确、函式是否异常..等),主要是因为 TSQL 并非程序性语言,它无法告知数据库应该用什么样正确步骤来撷取数据,所以这阶段会帮你处理基本语法优化、数据型别转换,简单来说就是会改写 TSQL,如把 between 转换为 >= and <=,型别比较不一致时,自动增加转换函数来确保数据正确性 (这就可能会大大影响查询效能), group by 位置..等,最后将输出逻辑 (操作) 查询树,后面将会依照所输出逻辑查询树步骤来一一执行。
查询优化
查询优化几乎可说是最复杂且耗时的阶段 (所以大家要有一点想象力),一开始会先确认计划快取区是否有适当的执行计划,如果没有找到适当执行计划,就会进行一般优化 (如果可以的话),然后再次从计划快取区寻找是否有适当的一般计划,如果存在就会分配相关内存并执行,这是因为不必为只有一种可能执行方法的TSQL进行完整优化,如此一来可以省下编译和建立执行计划时间,因为我们知道查询效能一部分取决于建立执行计划效率 (执行查询时间是产生执行计划时间 + 本身数据查询时间),所以查询优化器并不会寻找最佳执行计划,而是尽可能寻找最低成本 (以 CBO 为基础的 CPU、I/O 成本) 及传回结果速度最快的执行计划,如果该TSQL有达到一般计划条件的话,那么查询优化器将可不必进行完整优化而浪费不必要时间,下面我简单列出建立一般计划的情况
1. 只有查询单一数据表,且没有任何 order by or group by。
2. 只有查询单一数据表,且该数据表没有任何索引。
3. 只有查询单一数据表,且符合 SARG (search argrment) 格式及条件比对使用唯一值 (unique key)。
4. 查询只使用系统默认函示 (如 select getdate()..)。
5. 使用 insert..values 只新增单一数据表数据。
现在我们知道,如果查询语法符合一般计划的情况,那么SQL Server在建立计划时将会省下很多时间,但如果不符合的话,SQL Server将针对该查询撷取所有可用统计值数据(字段和索引),并先从计划快取区寻找是否有符合该查询的执行计划,如果有找适当执行计划的话,就在判断是否需要经过完整优化 (如查询使用了recompile 提示就必须进行完整优化),如果没有找到适当执行计划的话,那么就必须进行完整优化,这个时候查询优化器,会以所输出的逻辑查询树为基准,自我设计各种可能执行的方法,虽然这里会产生多种排列组合,但之前有提过,SQL Server并不会寻找最佳执行计划,因为寻找最佳执行计划所花费时间成本可能还会高出本身查询所需时间成本,所以只会寻找最低成本执行计划。
为了加速这处理过程,SQL Server将会采取平行处理来建立执行计划,前提是Server有多核心且cost threshold for parallelism and max degree of parallelism两个参数设定正确。
一般会选择非平行执行计划,但如果非平行计划成本超过平行计划成本,那么SQL Server将会把负载传送给每个可用CPU,这时将会建立平行执行计划,一般来说,在OLTP环境中需特别注意采用平行执行计划的查询,因为大多数都是不良TSQL、不正确索引或索引遗漏..等造成 (发生高 CPU 情况)。
当完整优化后将产生低成本适当的执行计划,这时就会将该计划存放到计划快取区中,并继续下一运行时间。
计划快取和查询执行
取得相关执行计划后,这时就会将该计划送给储存引擎,由储存引擎来执行该查询并且返回使者所需的数据结果集,这里须注意SQL Server可能会改变当初估计的执行计划,如果有达到以下条件
1. 所需数据表和字段统计值过时。
2. 执行期间所触及数据或统计值异动过大。
3. 非平行执行计划运行时间超过 cost threshold for parallelism 设定值。
如果执行期间数据、统计值异动过大,将会导致发生重新编译,你可以想象在最后一步骤才知道需要重新编译的话,这无疑对效能是一大伤害。
再来就是计划快取区只保留最常执行的查询计划,太久没执行的查询计划可能会自动清除,底下有几个情况会自动清除计划快取区,并再次发生完整优化处理
1. 当缓冲池 (buffer pool) 针对另一对象需要更多内存
2. 当查询计划不被任何联机使用
3. 当查询计划成本因子为 0
这里简单说明一下计划成本因子,每个执行计划都有该成本因子,每一次执行该执行计划就会自动累加1,SQL Server并不会自动递减该成本因子,但如果计划快取区大小达到buffer pool大小50%时,当下一次计划快取区被存取时,这是就会将快取区所有执行计划的成本因子都减1,这时如有成本因子为0的就会被清除掉。
为了要善用计划快取区,所以我们要尽量避免SQL Server发生内存不足问题,如果你遇到内存压力问题,可以开启optimize for ad hoc workloads (SQL 2008 以后才有) 来减轻内存压力
-- 开启optimize for ad hoc workloads
sp_CONFIGURE 'show advanced options',1
reconfigure
go
sp_CONFIGURE 'optimize for ad hoc workloads',1
reconfigure
go
select * from master.sys.configurations
where name='optimize for ad hoc workloads'
go
同时我们也要避免在正式环境中手动清除计划快取区 (使用 DBCC FREEPROCCACHE),因为这将导致所有查询都需要重新编译且降低查询效能。
再来就是我们要尽可能提高执行计划重用率并小心误用错误执行计划所造成效能问题,我简单整理以下 5 点可帮助你执行查询时,提高执行计划重用机率
1. 避免 ad hoc 查询类型
2. 动态组 SQL 字符串请使用 sp_executesql 取代 exec
3. 查询异动值请明确使用参数取代
4. 尽量使用 SP 但须注意参数探测问题
5. 尽量使用两字节表示 (dbo.usp_getdate),避免隐式解析
SQL 2014 查询优化器改善 -- 新基数估计算法
取得最低成本执行计划虽然对大多数情况来说是好的,但并不表示该计划一定是最佳的,为了取得更好执行计划,SQL 2014采用新基数估计算法来进行改善,简单来说就是查询效能会比以前的版本更好,而以前的SQL Server版本都将会遇到旧基数估计演算(Plan Regressions)而造成的效能问题,该问题详细可参考 [SQL SERVER]统计值能吃吗? 一文。
SQL 2014 in-memory OLTP 引擎
SQL 2014可以让我们建立in-memory数据表来优化OLTP效能,这意味者过去数据表使用硬盘存放并有高资源竞争问题都将获得改善,最大改变就是in-memory数据表将不会有任何latch和lock,那你可能会担心交易过程数据一致问题(ACID),这部分在SQL 2014则是使用Multiversion Concurrency Control (MVCC)技术来隔离交易不被干扰,同时也避免lock问题,也可让任何用户随时存取in-memory数据表资源,因为内存中的操作对用户来说都是一闪即逝的过程 (短暂交易最有利),用户几乎不会有任何等待的感觉出现。
SQL 2014还提供了原生编译的储存程序,透过原生编译的储存程序来存取in-memory数据表可将效能提高是以前版本约50%效益(微软官方数据),主要是因为产生的机器码(machine code),只针对该查询建立应该要执行处理器指令 (无须进一步编译或解释),可以更有效率执行查询,并且更快速得撷取数据,下面我们会使用in-memory OLTP引擎来简单测试不同持久性设定并执行新增数据效能差异。
建立in-memory DB和Table (schema_and_data & schema_only)
CREATE DATABASE memoryDB
ON PRIMARY (
NAME = [E:\SQLDataFile\memoryDB_data]
,FILENAME = 'E:\SQLDataFile\memoryDB_data.mdf'
)
,FILEGROUP [memoryDB_FG] CONTAINS MEMORY_OPTIMIZED_DATA (
NAME = [memoryDB_dir]
,FILENAME = 'E:\memoryDB_dir'
)
LOG ON (
NAME = [memoryDB_log]
,Filename = 'E:\SQLDataFile\memoryDB_log.ldf'
)
GO
CREATE TABLE MemorySchemaAndData
(
id int NOT NULL,
c1 nchar(1) NOT NULL,
CONSTRAINT PK_MemorySchemaAndData PRIMARY KEY NONCLUSTERED HASH (id) WITH (BUCKET_COUNT = 150000)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
CREATE TABLE MemorySchemaOnly
(
id int NOT NULL,
c1 nchar(1) NOT NULL,
CONSTRAINT PK_MemorySchemaOnly PRIMARY KEY NONCLUSTERED HASH (id) WITH (BUCKET_COUNT = 150000)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
进行测试之前我简单说一下建立in-memory数据表注意事项
Schema_and_data:OLAP系统中,该内存数据表类型最常被使用,透过持久性选项设定,可以确保SQL Server发生崩溃后相关数据表结构和数据依然会保留。
Schema_only:内存中只存放数据表结构(metadata),SQL Server发生崩溃后相关数据会消失。
前面我们有提到,in-memory OLTP引擎会建立machine code,所以每一个in-memory数据表都有一颗相对应dll (如下图),当该数据表被加载时,可以避免编译或解释,因此可以更快取得查询数据,同时因为都会被加载到内存中,所以限制每个数据表内存大小也是相当重要的事,微软有提供一个 估算内存大小公式 ,当你要将数据表移转到in-memory数据表时,还请不要忘记该重要环节。
测试新增数据到 in-memory 数据表
Schema_and_data
DECLARE @step INT
SET @step = 1
WHILE @step <= 120000
BEGIN
INSERT INTO dbo.MemorySchemaAndData
VALUES (@step, '1'),
(@step+1, '2'),
(@step+2, '3'),
(@step+3, '4'),
(@step+4, '5')
SET @step = @step + 5
END
12万笔约花8秒。
Schema_only
DECLARE @step INT
SET @step = 1
WHILE @step <= 120000
BEGIN
INSERT INTO dbo.MemorySchemaOnly
VALUES (@step, '1'),
(@step+1, '2'),
(@step+2, '3'),
(@step+3, '4'),
(@step+4, '5')
SET @step = @step + 5
END
12万笔几乎0秒。
确认in-memory数据表数据
当in-memory数据表使用schema_only选项时,新增数据处理几乎没花费任何时间,但我前面有提到过,schema_only在SQL Server发生崩溃后,将不会保留任何数据,所以当你使用该选项时必须要清楚了解该特性,以免发生数据无法复原的惨剧。
重新启动SQL Server DB (仿真 SQL Server 崩溃),并确认in-memory数据表数据状况
Use Master
go
ALTER DATABASE memoryDB SET OFFLINE WITH ROLLBACK IMMEDIATE
GO
ALTER DATABASE memoryDB SET ONLINE
GO
使用Schema_only的in-memory数据表数据都无保留。
TSQL on Azure
如有你有使用Azure SQL Database的话,那么在撰写TSQL时需要留意以下几个重点。
1. 善用数据表值参数
SQL 2014有加强数据表值参数(SQL Azure 也一样),就是数据表值参数可以使用索引来提高查询效能,以前大家可能比较常用temp table来处理元数据,但在Azure上需要当心使用过多的tempdb资源,毕竟tempdb只有一个 (大家共享),所以当使用过多tempdb资源时,Azure可能会自动切断联机,所以建议使用数据表值参数取代temp数据表来处理元数据。
2. 减少数据网络来回次数
由于网络质量我们无法掌握,所以一定要减少数据在Azure和Client之间的往来次数,同时也要建立一套安全retry机制,基本上都建议采取批处理 (如一次捞所需的数据结果集),少用row by row方式 (这也增加 Azure 费用成本) 来查询数据或进行数据异动 (如c ursor),且所有TSQL请使用try.. catch包起来,如遇到问题 (如网络断线..等)才可以有相对应处理方法。
3. 善用快取
可以在数据表中新增 rowversion 字段,这样我们就可以轻易使用该字段(注意该字段不建议成为索引键值)来判断上次读取数据列后,数据列中任何值是否有改变,如果没有改变的话就读取本地快取数据,否则就读取Azure上数据,这不仅可以大幅提高效能,同时也可以省下不少 Azure 费用成本。