如何写出高效能TSQL - 关于索引不可不知道的事
原文地址:https://blogs.technet.com/b/technet_taiwan/archive/2015/01/23/tsql-series-0123.aspx
本文将分成五大单元,分别带您了解:
简介
TSQL是查询SQL Server的核心,而索引则是提高查询效能的主角,如要写出高效能TSQL则无可避免需搭配正确索引,因为SQL Server需透过正确索引才可以快速有效地找到与索引键值相关数据,有了正确索引SQL Server就不需要扫描数据页(data page)上每一笔数据,而在众多查询效能调校技术中,透过建立并设计正确索引算是最基本的手法 (通常来说也是最有效、最快能看到效果的),所以了解索引观念和特性,可以帮助我们在开发阶段设计规划正确索引,而且我们认为不管是开发人员或DBA都应该了解索引该如何设计,因为都有可能接收用户最直接的感受,说白话一点,每一句查询TSQL都要以最短时间响应给用户。但由于索引主题范围庞大,所以一开始我们会介绍索引基本知识、B-tree 结构等,后面介绍索引类型、案例分享及设计须注意的方向,主要是希望透过本文可以让大家快速建立正确索引。
索引基本知识
SQL Server 如何使用索引
我们都知道索引可以提高查询效能,但相对也增加新增(Insert)、删除(Delete)和更新(Update)数据处理成本,所以对整体效能来说找一个合适平衡点相当重要。
当一个数据表没有索引时,数据存放的顺序绝不是依照数据新增顺序,这是因为SQL Server Database Engine会自我处理数据储存位置,所以基本上,我们无法事先预测数据储存在数据页上是否都连续且都在同一区段中,而当一句Select送给SQL Server时,因为没有索引,这时SQL Server必须扫描整个数据表,以及该数据表的所有数据页和数据页上的每一笔数据,最后才返回用户最终所需要的数据结果集,这样的操作就称为表扫描(Full Table Scan)。
当数据表上有索引时 (假设索引设计正确),这时数据表上的数据一定会经过排序,所以SQL Server将基于该索引键值和结构来定位 (透过指针) 数据位置,简单来说只搜寻必要的数据页,而这些数据页已经包含用户最终所需要的数据结果集,这样的操作就称为索引搜寻(Index Seek)。
B-tree 索引结构
SQL Server所有索引基本上都采用B-tree结构,除了xml索引、全文检索索引(full-text)、数据行存放区索引(columnstore index)和内存优化索引(Memory-optimized indexes)不用B-tree。 xml 索引是存放在 SQL Server 底层数据表,全文检索索引是利用自己引擎来处理查德询和管理全文检索目录 (full-text catalogs),数据行存放区索引则是使用 in-memory 技术,内存优化索引则是使用 BW-tree 结构。
一个标准的B-tree结构 (图1)是由根结点(root)开始的页面,下面有一或多个中继层节点及一或多个分叶(Leaf)节点构成。
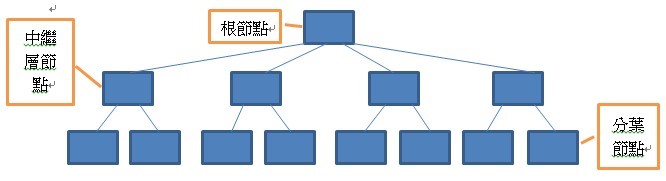
图1 B-tree结构。
一个B-tree结 构一定是平衡的,这代表每一层左右页面数量一定相等,最末的分叶页面包含了排序后的索引数据,每页索引数据列数量视索引所含数据行的储存空间而定。
根节点及中继层节点包含其下层节点的第一项数据,即表示指向下层数据储存位置的指针 (图2),SQL Server执行查询时会先扫描每一个根节点所在页面,搜寻是否含有查询的值,找到后再以指针指向下一层继续搜寻,如此不断反复处理,直到在最末层的分叶节点中找到数据为止。
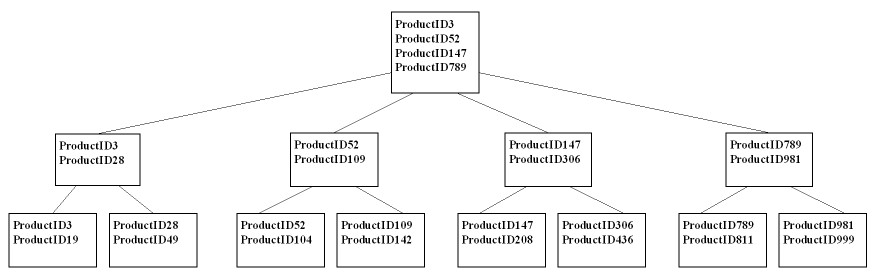
图2 索引页面中的根、中继层和分叶节点。
假设今天我们要在图2中搜寻ProductID199,查询会从根节点开始搜寻,因为ProductID199介于147~789之间,所以SQL Server会从ProductID147开始搜寻并计算Product199可能位置,指向下层 (中继层) 由ProductID147开始搜寻至ProductID306节点后,再指向下层 (分叶层) 搜寻ProductID199所在位置(147~208),由于此时已在最末层,故可以在该层找到数据,且SQL Server也不需要去搜寻其他节点或页面找ProductID199。如果 ProductID199 不在数据表中,查询就会回传找不到的结果,而 B-tree 的平衡效果,使得 SQL Server 每次在索引内搜寻数据动作时都只会在相同数量的各层索引页内处理,以利精准地找到所需数据。
更优的 Bw (Buzz Word) - tree
Bw-tree为内存优化索引和数据表带来重大改善,简单来说Bw-tree结构可以更省储存空间(内存)、更有效利用多核心且针对范围(range)和指针(point)搜寻有很高效率。
Bw-tree结构 (图3)和B-tree类似,所有分叶节点依然还是数据页(data page),其他index node只存放key (有顺序) 和下一页指针,且每页都透过一个逻辑指针(PID)串联一起,透过该PID对应Mapping Table即可找到数据存放的物理位置。
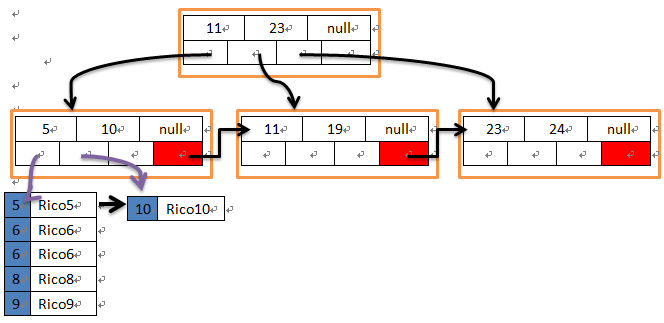
图3 Bw-tree 结构。
页面分割
SQL Server每页可储存8060 bytes数据 (大小为8092 bytes),如果以INT类型的数据行建立索引,数据表每一列数据就需要4 bytes的索引储存空间,假设数据表有2016笔数据 (需 8064 bytes 储存空间),因为索引词条已无法容纳于一页内,则必须进行页面分割,所以会加入两个新索引页面,在现有的根节点页面下移成为分叶层页面,并将原索引页面的一半数据,移至新产生的分叶层页面上,而在上层的页面则成为新的根节点页面,最后则是将每一个分叶层页面的词条写入至新的根节点页面。所以总共使用三个索引页面,一个根节点页面和两个分叶层页面 (这时不需要中继层页面,因为根节点页面可包含全部分叶层页面的词条),所以在搜寻数据时,最多会在两个页面执行,但如果页面分割发生频率过高将严重影响效能,所以设计索引上一定要考虑减少页面分割发生频率。
Note:页面分割不仅影响效能,同时也会影响交易纪录档案大小,该案例可参考 [SQL SERVER][Memo]页面分割影响事务历史记录档大小 。
索引类型介绍
丛集索引
数据表存在丛集索引,那么数据就会依照丛集索引键值顺序存放,该索引分叶层包含数据页(data page),所以当透过丛集索引搜寻数据即会返回数据真实存放位置,这样的特性即表示一个数据表只能有一个丛集索引,虽然并非每个数据表都一定要有丛集索引,但如有符合以下条件时,建议最好建立:
1. 大数据表且没有任何非丛集索引 (nonclustered indexes)
当你要查询相关数据时,如果没有丛集索引,那么就会进行表扫描,将从数据表第一笔扫描到最后一笔数据才能返回相关所需数据。
2. 针对某些字段常使用范围搜寻
有了丛集索引就可以避免整个数据表的物理数据排序处理,因为数据已经预先依照丛集索引键值排序过了。
3. 针对某些字段常使用 group by
数据要group by需先经过排序处理,而丛集索引将可省下排序处理。
4. 针对某些字段常使用排序
因为丛集索引已经排序了相关数据,所以查询一开始就可以避免排序处理。
建立丛集索引键值前需决定丛集索引键值 (相当重要的事),因为数据存放顺序会依照所选择字段来排序(降或升幂),虽然选择丛集索引键值没有一定的标准,但大致上还是方向可循,下面是我自己用来选择丛集索引键值准则:
1. 排序、群组
2. 唯一性
3. 不可 null
4. 避免宽索引
5. 数据异动少
6. 考虑 insert 数据排序 (最小碎片)
Note:当你定义数据表PK (Primary key)时,SQL Server默认会自动建立丛集索引。
非丛集索引
非丛集索引不排序或存放任何数据,索引页(index page)上所有分叶节点只存放指针,如果数据表已存在丛集索引,那么该指针将会指向丛集索引,如不存在将指向数据真实存放位置,所以建立丛集和非丛集索引顺序相当重要。
综合索引
该索引可以有两个以上字段,字段顺序请依照选择性高低摆放 (选择性高越前面),如果查询有需要多字段时即可建立提高效能。
范例:
select FirstName,LastName
from Person.Person
where FirstName like 'r%' and LastName like '%z'
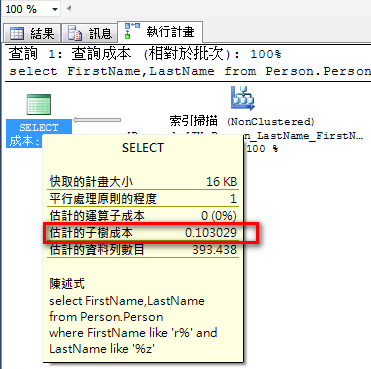
使用索引扫描、执行计划成本:0.103029。
依照该TSQL建立复合索引:
create index idx1 on Person.Person(FirstName,LastName)
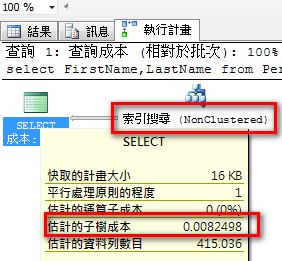
改用索引搜寻,执行计划成本降低为0.0082498
Note:密度和选择性可参考 [SQL SERVER] [Performance]密度和选择性 一文。
单一索引
该索引只有一个字段,针对单一字段搜寻数据很有用。
范例:
create index idx2 on Person.Person(FirstName)
{kind=link}
涵盖索引
涵盖索引算是使用率最高的索引类型,建立索引时透过include子句来扩充非索引键字段,SQL Server会将非索引键字段存放在索引上的分叶阶层 (不会每一笔索引列都存在),该层级几乎可说是索引叶上的最末层,且include只支持非丛集索引类型,涵盖字段有以下特性:
1. 索引键不受限 900 byte 限制,因为不会存放在 root 或中继层。
2. 可包含计算数据行,但数值必须有一定性。
3. 不能涵盖 text、ntext 和 image 数据类型。
4. 不能涵盖索引键值。
范例:
select FirstName,LastName,Title,PersonType
from Person.Person
where MiddleName='A' and EmailPromotion>=1
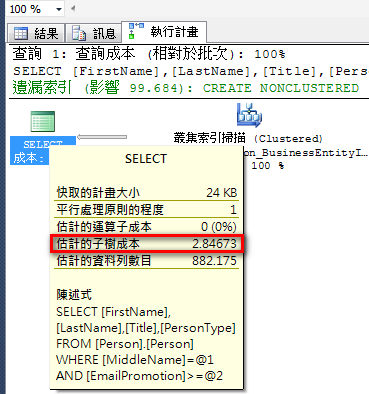
使用丛集索引扫描、执行计划成本:2.84673。
建立涵盖索引
create index idx3 on Person.Person(MiddleName,EmailPromotion)
include(FirstName,LastName,Title,PersonType)
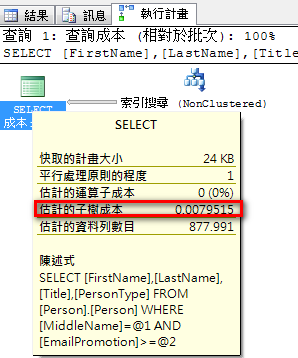
改用索引搜寻、执行计划成本:0.0079515。
唯一索引
该索引可以强制索引键字段具有唯一性,当你定义唯一约束默认会建立唯一非丛集索引,或数据表没有丛集索引且定义PK默认也会会建立唯一丛集索引,该索引一般来说会大幅提高效能 (可以产生很有效的执行计划),如果你确定相关字段具有唯一值,且查询也需要这些字段,那么建立唯一索引绝对不会错,唯一索引特性如下
1. 可以使用单一或多个字段
2. 可以为丛集或非丛集 (包含 include)
3. 索引建立 (或重建) 期间,会确认索引键字段是否有重复值
4. 数据新增或更新期间,会确认索引键字段是否有重复值
筛选索引
筛选索引是优化的非丛集索引,但索引弹性相对低,所以实务上实用性较低的,但针对已知且固定的数据子集,建立筛选索引确实可以大大提高查询效能并减少索引使用空间,案例参考 [SQL SERVER][Memo]筛选索引一文。
分割索引
建立分割数据表并在该数据表上建立索引 (建议包含 (include) 分割数据行),SQL Server默认会使用相同的分割结构(partition scheme)和分割数据行(partition column)自动对索引进行分割,主要是希望索引和数据表对齐(aligned),索引和数据表对齐对效能来说相当重要,分割索引不只可以提高询效能,也可减少索引管理成本,因为你可以针对某区索引碎片执行重建操作,进而减少某种程度的SQL Server停机时间。
数据行存放区索引
SQL 2012新增的数据行存放区索引主要是提高OLAP效能,储存方式不像以往采取row,而是改成column方式储存,这会大大提高缓冲命中率并减少I/O,同时对于完整扫描作业可以带来极大效能效益,但建立该索引后,数据表会变成唯独,这个限制导致不太适用在OLTP环境中,但开心的事在SQL 2014移除了这项限制,这改善真是大快人心。
范例:SQL 2014数据行存放区索引数据更新测试
create table mycolumnstore
(
c1 int identity(1,1),
c2 varchar(30),
c3 date
)
--建立columnstore index
create clustered columnstore index cidx_cs
on mycolumnstore
新增操作
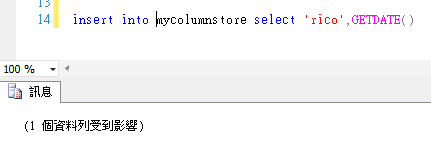
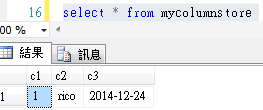
更新操作
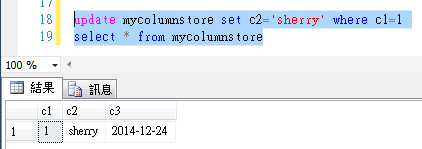
删除操作
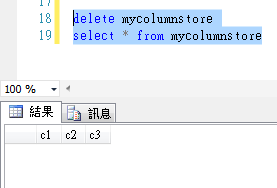
内存优化索引
SQL 2014内存优化索引使用Bw-tree结构,所有逻辑指针都存在内存中,总共有两种非丛集索引类型。
1. 非丛集哈希 (hash)索引:
该索引适用指针查阅,大小固定且没有任何页面(page),查询返回的值都是没有排序。
2. 非丛集非哈希 (hash) 索引:
该索引适用范围或排序扫描,也适用任何符合SARG查询参数,查询返回的值都会排序。
范例:
--建立内存优化数据表
CREATE TABLE [TransactionHistoryArchive] (
[TransactionID] [int] NOT NULL
CONSTRAINT PK_TransactionHistoryArchive primary key NONCLUSTERED HASH WITH (BUCKET_COUNT = 100000),
[ProductID] [int] NOT NULL,
[ReferenceOrderID] [int] NOT NULL,
[ReferenceOrderLineID] [int] NOT NULL,
[TransactionDate] [datetime] NOT NULL,
[TransactionType] [nchar](1) NOT NULL,
[Quantity] [int] NOT NULL,
[ActualCost] [money] NOT NULL,
[ModifiedDate] [datetime] NOT NULL index idx1,
index idx2(TransactionID),
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
--新增数据:内存数据表的交易无法跨数据库
SELECT * INTO mytemp
FROM AdventureWorks2012.Production.TransactionHistoryArchive
INSERT INTO TransactionHistoryArchive
SELECT * FROM mytemp
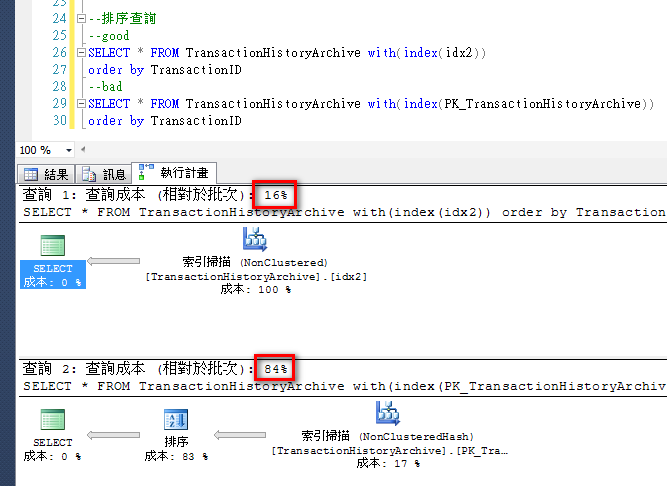
--排序查询
--good
SELECT * FROM TransactionHistoryArchive with(index(idx2))
order by TransactionID
--bad
SELECT * FROM TransactionHistoryArchive with(index(PK_TransactionHistoryArchive))
order by TransactionID
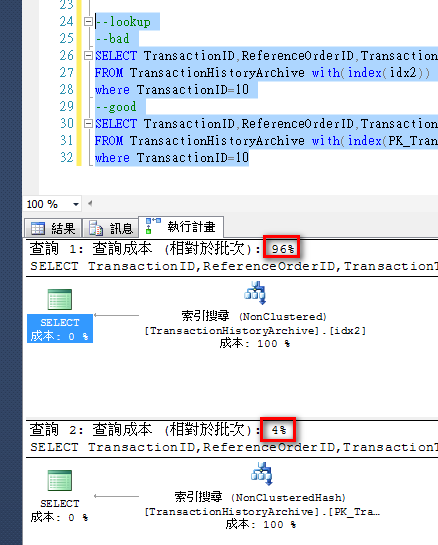
--lookup
--bad
SELECT TransactionID,ReferenceOrderID,TransactionType,ActualCost
FROMTransactionHistoryArchive with(index(idx2))
where TransactionID=10
--good
SELECT TransactionID,ReferenceOrderID,TransactionType,ActualCost
FROM TransactionHistoryArchive with(index(PK_TransactionHistoryArchive))
where TransactionID=10
索引设计注意事项
索引设计基本上需对应数据存取TSQL才能到位,这里提出一些索引设计须注意相关事项让大家参考:
1. 先建立非丛集索引后建立丛集索引
前面索引类型内容有提到,当一个数据表没有丛集索引时,先建立非丛集索引的分叶层页面指针将指向真实数据位置,如丛集索引已经存在时将指向丛集索引,先建立非丛集索引可以避免当你重建丛集索引时,连带影响非丛集索引一起重建 (须注意索引两次重建问题),这不仅拉长重建索引时间,也增加交易纪录档大小且浪费硬盘空间。
2. 使用索引压缩
使用索引压缩可以提高缓冲区命中率 (缓冲区可存放更多词条) 并减少I/O和硬盘空间,建立索引时可以善加利用,但由于压缩操作需要使用较多CPU资源,所以须注意CPU资源竞争情况。
索引压缩测试:
--建立数据表
create table test1
(c1 int null,
c2 varchar(10) null)
--新增数据
declare @i int
set @i=1
while @i<2016
begin
insert into test1 values(@i,null);
set @i=@i+1;
end
--建立非丛集索引不使用压缩
create nonclustered index nidx_1 on test1
(c1)
--查看索引页面数(page_count)和其他相关信息,确认压缩所带来的优势
SELECT o.name,
ips.index_id,
ips.partition_number,
ips.index_type_desc,
ips.record_count, ips.avg_record_size_in_bytes,
ips.min_record_size_in_bytes,
ips.max_record_size_in_bytes,
ips.page_count, ips.compressed_page_count
FROM sys.dm_db_index_physical_stats (DB_ID(N'AdventureWorks2012'), OBJECT_ID( N'AdventureWorks2012.dbo.test1'), NULL, NULL, 'DETAILED') ips
JOIN sys.objects o on o.object_id= ips.object_id
ORDER BY index_id asc,record_count DESC ;

页面总数量5,每笔数据平均大小16 (bytes)
--建立非丛集索引并使用页面压缩
create nonclustered index nidx_2 on test1
(c1)
WITH ( DATA_COMPRESSION = PAGE ) ;
使用页面压缩可以看到每笔数据平均大小从16降低为9.434,页面数量从5降低为3。
3. 设定填满因子 (Fill Factor)
透过设定填满因子可以微调索引效能和储存空间,该因子会决定分叶层页面填满数据的空间百分比 (保留每个页面可用空间),以利未来数据成长使用,主要目的是要减少页面分割发生频率,如设定90 (默认 0)表示只预留10%空间比例,实务上我建议该值依数据表读写特性设定比较有效益,因为设定过低将增加页面分割频率,也造成索引碎片过多增加I/O,进而影响查询效能且容易发生长时间Lock资源情形,但设定过高也会影响数据异动效能,所以建议必须依数据表读写特性设定取得一个平衡值,下面是填满因子建议值:
a. 只读或静态数据表: 设定 100%
b. 异动频率很低的数据表: 设定 95%
c. 异动频率一般的数据表: 设定 85%~90%
d. 异动频率很高的数据表: 设定 50%-80%
4. 索引键字段最好用于 join 操作
Join多个数据表是常见的情况,当建立非丛集索引时最好第一优先考虑这些join字段,或是设定Foreign key约束,这样才能让索引发挥效益并大大改善查询效能。
5. 善用涵盖索引
涵盖索引include字段不受900 bytes限制,且又可满足查询所需数据字段,即不须额外浪费时间搜寻data page,该索引效益永远比单一字段索引来的高,而且更有弹性。
案例可以参考 [SQL SERVER]提高动态查询效能
6. 优先考虑选择性高字段
Distinct、where、order by、group by和like子句相关字段最好选择性高,高选择性字段可以让索引更有效益,主要可以让统计值估计更准确。
7. 适时重建索引
当在数据表中删除一笔数据时,SQL Server必须由索引页中移除该笔数据的索引数据,而这就会导致在索引页中留下空白,由于填补新值的成本太大,所以SQL Server也不会去填补该空白,若在数据表中更新一笔数据时,则SQL Server必须在索引页中搜寻适当的位置并加入,而这也有可能会造成另一段空白。当索引页已满且必须进行分割时,就会产生更多的索引碎片,当碎片过多就会影响查询的效能 (因为跨多个索引页,所以增加 IO 读取),所以当数据表数据异动频繁时,时间一久,就会造成索引不断破碎 (空白太多),这时候建立要执行重建索引操作。
索引碎片又分两种类型,内部碎片和外部碎片。
外部碎片:
由于索引数据都是经过排序的,如果你的分叶层页面(index leaf page)实体排序和查询所要求的逻辑排序不相同时,就会导致SQL Server有额外的工作来返回正确的排序结果,但在大多数的查询情况下,内部碎片并不会太大,但在设计索引上还是得注意排序的需求。
内部碎片:
一般来说索引页都会预留一定的空间来存放新增(insert)的数据,因为这可以减少页面分割发生的频率,所以当你在建立或重建索引时,你可以指定填满因子(Fill Factor)来决定一张索引页面可存放多少百分比数据,如果索引页面过于分散,将会拉长查询时间 (跨多索引页面,并增加额外的 IO 读取),而且也会造成你的索引过于肥大 (浪费硬盘空间),请务必减少页面分割发生的频率,因为页面分割这样的动作相当耗费系统资源。
进阶推荐
若您有兴趣进阶学习,可参考MVP James Fu录制的数据库例行管理系列教学之索引维护篇,除了教学影片,亦提供了简报档下载,都是完全免费的,欢迎多多运用。

希望以上内容对您的学习有所帮助。