The art of proxying
In a web developer's life proxying is a technique that sooner or later will become important, in some cases even necessary depending on project's scale and complexity. In this article I will cover basic theoretical aspects about proxies, and illustrate how they work and what applications they have in real life.
Basics on proxies
A proxy is a generic entity used to act as a (possibly transparent) third party component in the context of a whatever interaction. However, when using the term proxy, people usually refer to web proxies. A web proxy basically is a web server which intermediates in HTTP communications between different hosts. The basic idea behind a proxy is having host A communicate to host B through a server (the proxy): this architecture enables several scenarios, useful for developers, that I am going to illustrate.
There are basically two possible ways a proxy can be configured, but it is good to start from the basic scenario when no proxy is involved.
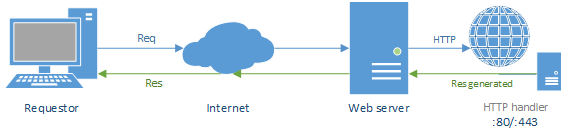
A normal HTTP session involves a requestor and a web server. An HTTP request is sent to the web server (the requestor needs to know the address of the web server), which replies back with an HTTP response. In this model, a proxy can be placed in different locations: this will determine the type of proxying strategy being used.
Reverse proxy
A reverse proxy is an Internet-facing device acting as an intermediary on our side of the LAN, handling requests and dispatching them to one of our hosts in the same network. This scenario is illustrated below.

As you can see, the proxy is placed right after the LAN gateway and dispatches messages to the server. This is the most common configuration for a proxy due to the as well very common scenario it supports: hiding resources. A reverse proxy in such a configuration can be an interface for the world outside. When a client requests a web page or something else through HTTP (this is also valid for other application protocols), it will not use the IP address of our web server, but the IP address of our proxy; we can then protect our important servers in the LAN giving them private addresses as our proxy will dispatch messages to them. The final result is that our servers will not be exposed to the Internet, only the proxy will, but a proxy usually stores no significant data (differently from our servers), thus if it is successfully hacked, no data leakage will occur and our information will still be safe and not corrupted.
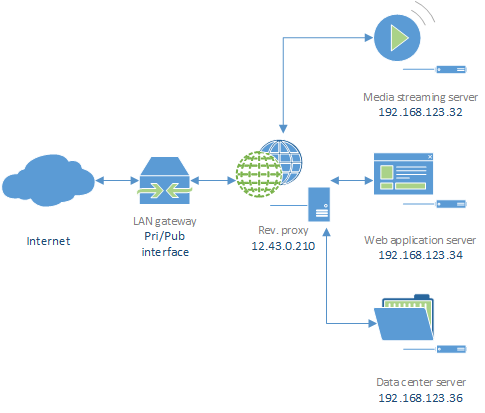
The image above shows one of the real usages of a reverse proxy: not only can it hide resources, it is also able to act as a dispatcher to many servers in our LAN. In this case the dispatching can be performed based on the URL provided in the HTTP request; consider you are developing a web application to download and stream music: www.listentomusic.com. We do not want our music files to be publicly exposed on the network, so we use a reverse proxy as shown in the picture. However we also provide music information other than the music itself, so when the user accesses our web site it will typically download pages from our web application server, however when he wants to listen to music, addresses will have the following format: www.listentomusic.com/listen/\<song-name>. Our proxy will then make a request to the media streaming server providing, in the HTTP header, all security parameters needed to get access to music files. When the user wants to access music info, he can type www.listentomusic.com/artist/\<name-of-artist> or www.listentomusic.com/song/\<name-of-song>, this will have the proxy redirect the request to the data center server instead.
Load balancing
Another very common strategy in networking involving reverse proxies is load balancing; a reverse proxy can be really handy in this case. Consider the situation depicted in the picture below: our service is expected to provide responses to a very high number of requests, in this case chances are that a single server is not enough, since we are a small business company, we cannot really afford a high-level performance server, however we can always rely on the Dividi et Impera approach: we can buy more average-performance servers and have the proxy balance the load.
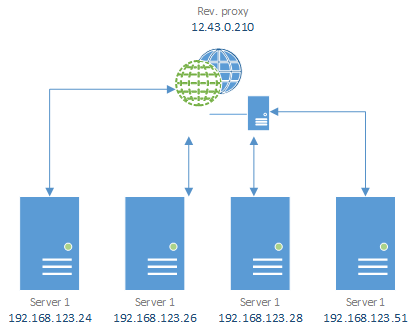
A reverse proxy improves security, resource protection and maintenance as well. Say for example that you need to migrate your server to a different system, your server will probably be down for 12 hours at least. No problem, you can create a cloned low-performance server for one day and redirect traffic there while you are migrating your real server: you will keep you service alive without users noticing as the proxy will redirect traffic on a different location while serving requests to the same public address.
Forward proxy
A forward proxy can be considered as the opposite of a reverse proxy: it is an Internet-facing device which redirects our requests to specific sources.
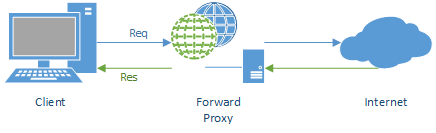
The purpose of such an architecture is having client's requests redirected (transparently to the client) to another location from the original one. Why? There are possible rationales.
- Anonymity This represents the 95% of reasons for which one would use a forward proxy and, sadly speaking, seeking for anonymity generally means that someone is willing to perform not so nice actions on the web. A forward proxy, in fact, will not let the server know who really is looking for a specific resource as the proxy will be seen as the requestor. Think of a forward proxy like a trader, it will protect your identity acting as an intermediate unit between you and the server.
- Source selection This application is not so common and is meaningful if you are a developer or a tester. If we were developing a distributed system, we could use a proxy as a traffic router to direct all requests to a specific source. This can be good when performing stress tests for example.
Open proxies
Forward proxies became very famous on the web when private subjects or companies started offering free forward-proxying service. Not so much time ago, network administrators used to block users' access to social networks, like Facebook, Google+ or Twitter, in corporate or university campus LANs. Usually this common practice was meant to improve bandwidth and prevent employees or students from taking too much leisure time on blogging or socializing during work/study time.
Achieving this block is easy: firewalls would not let in or out packets whose source/destination IP address is part of a blacklist. Well, we all know people are very smart especially when it comes to breaking the rules, in fact a solution to this problem (if we want to call it so) came very fast: using a forward proxy to access social networks.
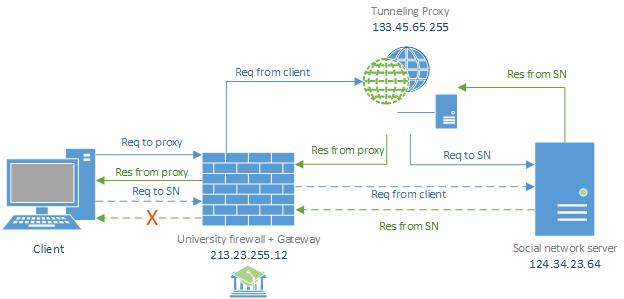
The figure above shows how it is possible to deceive the university firewall when getting access to our social network by relying on a tunneling proxy. An open proxy is in fact a tunneling proxy: it takes all requests and simply forwards them to a specific destination without changing them (only the source address will be changed). If we use a proxy, our request will not be directed to the social network's server, but to the proxy; the firewall will not block our request because it is not part of the blacklist. Also, when we receive the reply, we will receive it form the same exact proxy, this time as well the firewall will let the pack go through.
Few years ago there were many proxies available on the web to let people connect to social networks, however network administrators got a little smarter and firewalls today are also able to inspect the HTTP content of TCP/IP packets. Instead of relying on addresses, firewalls inspect the content of packets, thus they can access the HTML header in order to find traces of social networks. But it's not like this little war is over, more techniques have been implemented to work around these blocking systems. By the way, today employers prefer not to prevent their employees from accessing social networks, the same goes for students in universities: it is way cheaper to let everybody have their leisure time instead!
Proxy design and implementation
Designing a proxy is not so difficult, in this section I am going to describe the most common principles to follow when developing a proxy so that it works as expected.
Handling communications
A web proxy must ensure transparency and allow a communications between two hosts to take place when it is actually acting as a Man In The Middle. The figure below illustrates how a proxy should handle requests and responses.
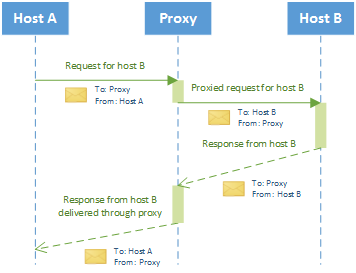
When a proxy receives a request it must hold it and, in the meantime, fire a new request to the real destination. After host A sends a request to the proxy (we are not covering a Man In The Middle attack, so host A is perfectly aware of the existence of a proxy), the proxy will take some time to hold the request and create a new HTTP request to host B. Host B will replies after a while (time necessary to retrieve the requested resource) and then the HTTP response lands on proxy, which will change the source address with its own and forward it to host A.
Ensuring association
The other thing a proxy should take care of are associations between requests and responses. Since a proxy is a server, it will process more than a request; for this reason a proxy must be able to correctly manage all session couples (hostA-Proxy and Proxy-hostB). In the figure shown before, we can see that a proxy handles two different sessions both sharing an address: the proxy; once a request is handled in the first session, it must be saved until the session with destination host terminates. It is important not to mix up sessions and keeping all couples consistent. Other than a communication problem this is a security issue as well.
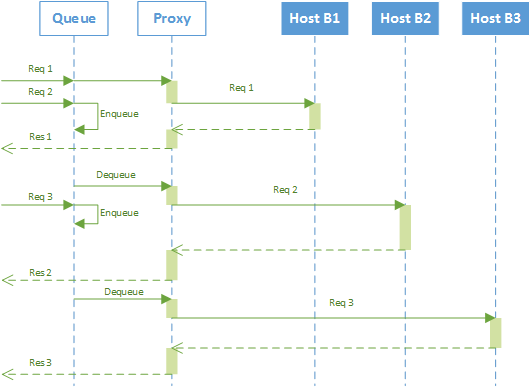
The figure above shows a proxy serving request using a queuing system. This can be quite a naive approach but it works: all requests are saved in a queue as they arrive. Whenever ready to process a new request, after terminating processing a full session, the proxy will take care of the next one. As all queues, it is important to know well the expected throughput so that queues can be sized correctly, otherwise the probability of data loss due to full queues can become very high.
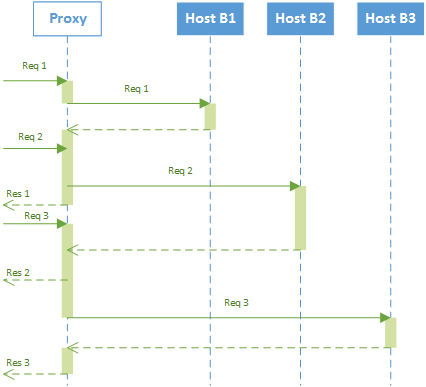
The approach shown in the picture above is now the opposite: multi-threaded proxy. Dispatching threads as requests arrive is a good idea; however there is a limit in threading due to shared resources. Modern proxies use thread pools in order to handle thread creation. It means that a new thread is not created every time a new requests arrives, modern algorithms evaluate the machine status and decide whether new threads should be created or reused.
The views and opinions expressed in this blog are those of the authors and do not necessarily reflect the official policy or position of any other agency, organization, employer or company.